院落ちた\(^o^)/ 受かった
SIMTってやつを完全に理解したい
最近(ここ20年くらい)、GPUでSIMTってのがアツい。アツいという事にしましょう。まあ興味を持って損するもんでもないでしょう。というわけで論文読んで理解しような。
良さそうな論文を用意したのでこいつらに疑問に答えてもらう。
SIMTとは
SIMTの概要をまずは知る。
“All current-generation GPUs operate according to the SIMT (Single Instruction, Multiple Threads) execution model. From the programmer’s and compiler’s point of view, this model is similar to SPMD (Single Program, Multiple Data). The programmer writes a single program or kernel. A large number of instances of the kernel (or threads) are then run in parallel. “
“(訳) プログラマの観点からはSIMTはSPMDに近く、プログラマはカーネルとも呼ぶ単一のプログラムを書き、そのカーネルが大量に並列に実行される。”
- Stack-less SIMT reconvergence at low cost
これは理解できる。vaddを実行するんじゃなくてaddを大量に並列に実行するんですね。OpenCLで見た。軽率にGPUを使っていこう、OpenCL入門
“During execution on a GPU, transparent hardware mechanisms group threads in convoys named warps to execute their instructions on SIMD units.”
“(訳)ハードウェアがスレッドをまとめてwarpと呼ばれる塊にして、命令をSIMDユニットで実行する。”
- Stack-less SIMT reconvergence at low cost
warpはスレッドの塊、OK。warpをSIMDユニットで実行、OK。
ちなみに、CPUの文脈のSIMDユニットとGPUの文脈のSIMDユニットは全く別物であることを知っておかないと大変沼る(一敗)。AVX-512に代表されるようなCPUにおけるSIMD命令は、演算器が横にズラッと並んだSIMD演算器とも呼ぶべき実行ユニットで実行される。対してGPUにおけるSIMDは、PEと呼ばれる比較的汎用的で小規模なプロセッサを並べて実現している。
このGPUにおけるSIMDの実現方法は1997年からそう。
よってwarpをSIMDユニットで実行とは、スレッドの塊がPEの塊に突っ込まれている光景を想像してくれればよい。個人的にはPEの塊をSIMDユニットと呼ぶなよと思う。
Simty: generalized SIMT execution on RISC-V の方では
“The Single Instruction, Multiple Threads (SIMT) execution model as implemented in NVIDIA Graphics Processing Units (GPUs) associates a multi-thread programming model with an SIMD execution model.”
“(訳)SIMT実行モデルはマルチスレッドプログラミングモデルをSIMD実行モデルに関連付けている。”
- Simty: generalized SIMT execution on RISC-V
とか
“The SIMT execution model consists in assembling vector instructions across different scalar threads of SPMD programs at the microarchitectural level.”
“(訳)SIMT実行モデルはマイクロアーキテクチャレベルでSPMDプログラムのスレッド群からベクトル命令を構成する。”
- Simty: generalized SIMT execution on RISC-V
とか言ってる。わからん。
多分SPMDなプログラムをそのまま実行できる計算機がSIMTなんだと思います。
SIMTの利点と欠点
とりあえずSIMTの概要を知ることが出来た。次はSIMTの何が嬉しいのか、そして何が辛いのか理解していく。
SIMTの利点と欠点は一言でまとめられている。
“Although this model offers a good balance of performance and programmability compared to classic SIMD instruction sets, handling thread divergence dynamically has a cost in area, power and hardware complexity.”
“(訳) 古典的なSIMD命令セットと比べると、SIMT実行モデルはパフォーマンスとプログラミングのしやすさのバランスが優れているが、スレッドの動的なdivergenceの扱いに回路面積・消費電力・複雑さにおいてコストを払う事になる。”
- Stack-less SIMT reconvergence at low cost
プログラミングはしやすくなるけど分岐の実装がダルいんですね。
divergenceとか謎の単語が出てきたが、divergenceは最初は足並みを揃えてたwarpのスレッド達が、分岐命令を実行することでプログラムカウンタの値が異なってくることだと理解してる。convergenceはその逆。
このdivergenceとconvergenceを管理する特別な命令を持つ命令セットが存在してないので、SIMT実行モデルの汎用プロセッサの採用が辛いみたいな事も書いてあるが、これをRISC-Vで解決するのがSIMTYである。
SIMTにおける分岐の実装
SIMTにおける分岐の実装にはどんなものがあるのか、Stack-less SIMT reconvergence at low costの2. Related workに紹介があるので読んでみる。
“We distinguish explicit methods, whose behavior is exposed at the architectural level and which require specific action from the compiler, from implicit methods, which are restricted to the micro-architectural level and can operate on standard scalar instruction sets.
Divergence control mechanisms address two distinct issues:
• In which order the control flow graph is traversed: which divergent branch will be executed first.
• How thread reconvergence is detected: when should divergent paths be re-united.”
- Stack-less SIMT reconvergence at low cost
このdivergenceの実装には明示的な方法と暗黙的な方法の2つに分けられ、明示的な方法はコンパイラによるアクションが必要らしい。多分分岐命令の前後に特殊な命令でも挿入すると思う。暗黙的な方法はそういうのが必要無い。
スレッドのdivergenceには2つの問題が存在する。
- 制御フローグラフをどの順序で走査するのか、つまりどの分岐を先に実行するか
- どうやってconvergenceを検知するか、つまり分岐したパスをいつ結合するか
これはわかる。制御フローグラフの走査順序はパフォーマンスにかなり影響する。convergence検知はよくわからないです。
“For techniques which allow function calls, the call stack can be implemented in two ways. The difference between the solutions appear in cases of recursion.”
- Stack-less SIMT reconvergence at low cost
関数呼び出しのためのコールスタックの実装は再帰の対処方法に着目すると二種類に分けられるらしい。
“Traditional parallel architectures share a single stack pointer per warp. This ensures that concurrent accesses to the call stack from different threads are always kept synchronized. On the other hand, this restricts SIMT execution to threads that share the same stack pointer in addition to sharing the same instruction pointer. Threads that are at different call nesting levels cannot run together. “
“(訳) 古典的な並列アーキテクチャではwarpで単一のスタックポインタを共有する。これで異なるスレッドがコールスタックへ同時にアクセスしても同期が常に保たれる。”
- Stack-less SIMT reconvergence at low cost
まあスタックポインタが1つだけならどのスレッドも関数呼び出し時は完全に全てのスレッドで同期される気がする、divergenceとの関係はよくわからない。
“(訳) 一方で、これはSIMTが実行できるスレッドを、同じスタックポインタかつ同じ命令ポインタを共有しているスレッドのみに制限する。関数コールのネストの深さが異なるスレッドを同時に実行することは出来ない。”
これは、この実装だと命令ポインタが同じでもスタックポインタが違う場合、例えばスレッド0とスレッド1で再帰の深さが違うような場合に、実行する関数は同じにも関わらずスレッド0の実行が完了してからスレッド1を実行しなくてはならず、これは明らかに効率が悪い。そういう意味だと思う。
“The other solution consists in maintaining an independent stack pointer per thread. In case of recursion, control divergence is reduced. It is replaced by memory divergence: accesses to the stack become irregular.”
“(訳) その他の手法としてスタックポインタをスレッド毎に持つ手法があり、この場合はcontrol divergenceが減少する代わりにスタックへのアクセスが異なるmemory divergenceに置き換わる。”
- Stack-less SIMT reconvergence at low cost
難しい、control divergenceは多分分岐命令時にプログラムの流れが分裂する事を指してる、memory divergenceは何だろう。スレッド0とスレッド1で深さの異なる再帰を実行していったらスタックポインタの値だけが異なって行きそう、多分これがmemory divergenceかな。
確かに再帰の対処って大事っすね。
明示的な方法, スタックベース
Pixar Chap
Pixar ChapなるPixar製の古の画像処理用プロセッサは、命令セットにif, else, fi, while-do, doneといった、プログラミング言語によくある制御構文を反映した制御命令を持っている。if-else-thenといった条件分岐はcurrent prediction maskが扱い、ループはtwo mask stackというものが扱うらしい。
Pixar Chapでは制御フローグラフの走査順序はISA側で明示して、ReconvergenceはISAに加えてmask stackで検知するらしい。謎。
謎すぎるのでCaroline Collange先生の資料を読んでみる。23ページあたりから読むとアツい。
あー完全に理解した。ありがとうCaroline Collange先生。
まずはシンプルな実行マスクを考える。このマスクはi-bit目が1ならi番目のスレッドが実行されるものであり、その値は分岐命令が実行されたときに変化する。以下の例では、最初のif文までは全てのスレッドが実行されるが、if文の条件式ではスレッド番号が2未満の場合に真となるため、実行マスクの値は[1100]となり、T0とT1しか実行されなくなる。その後if文を抜け、実行マスクの値は[1111]となるが、次のif文の条件式はスレッド番号が5より大きい場合に真となるため、実行マスクの値は[0000]となり、if文のブロックの最後まで、処理がスキップされる。

分岐命令時の実行マスクの変化
(GPU architecture part 2: SIMT control flow managementより作成)
次に、以下のようなif文がネストされ、またelseの存在するプログラムの場合に、実行マスクの値がどのように変化するか考えてみる。

if文がネストされたプログラム
(GPU architecture part 2: SIMT control flow managementより作成)
単一の実行マスクの実装の場合、else以前までは正常に処理されるが、elseの実行時点でアクティブになっているスレッドはT0のみであるため、T0のelseの評価は偽となり実行マスクの値は[0000]となる。その結果if文のブロックの最後まで、処理がスキップされる。結果的に本来ならばT1が実行するはずのelseの処理が実行されなくなる。

if文がネストされたプログラムの実行マスクの変化
(GPU architecture part 2: SIMT control flow managementより作成)
そこで実行マスクを保存するスタック、マスクスタックを用意する。このスタックの先頭に存在する実行マスクを有効な実行マスクとする。マスクスタックには、分岐時に新たに生成された実行マスクをpushし、コードブロックの終了時にpopする。
マスクスタックにより、2番目のif文の終了時に[1000]がpopされ[1100]が先頭となり、T0とT1がアクティブになる。そしてelseでT1では真となるため、[0100]がpushされてelse内がT1で実行される。結果的に全てのスレッドが正しく動作する。
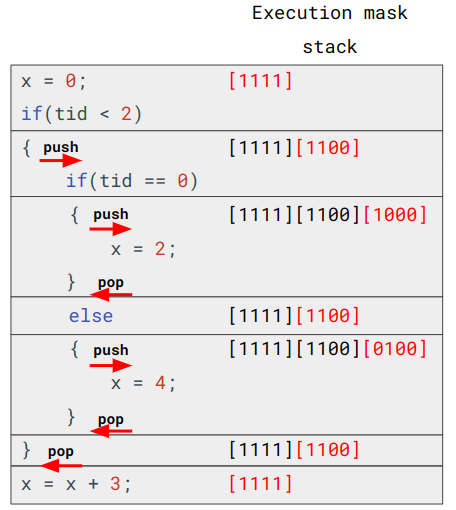
マスクスタック
(GPU architecture part 2: SIMT control flow managementより作成)
このmask stackの導入によりreconvergenceが実現できている。賢い。
まとめるとPixar Chapでは制御フローグラフの走査はISAで行い、Reconvergenceはmask stackで行っている。
現代のGPUではAMDが似たアプローチを取っている。実際にAMD Evergreenの命令セットを眺めてみるとLOOP_START命令とかある。
Evergreen Family Instruction Set Architecture: Instructions and Microcode
POMP
POMPはKeryll氏とParis氏が提案したPOMP並列計算機プロジェクトの産物であり、スタックに保存されているマスクは常にヒストグラムの形状を取る事から着想を得た。

マスクスタックの推移
(GPU architecture part 2: SIMT control flow managementより作成)
スタックのdepth \(d\)で非アクティブのスレッドはスタックのdepth \(d + 1\)でも必ず非アクティブのままとなる。つまり先頭が[1100]の状態で[1101]のようなマスクがpushされることは絶対に無い。
この性質のため、マスクスタックは各スレッドの最後にアクティブになったネストの深さを記録する、アクティビティカウンタに置き換えられる。

アクティビティカウンタ
(GPU architecture part 2: SIMT control flow managementより作成)
この実装により\(N\)をネストの深さとして、保存するデータ量をマスクスタックの\(O(N)\)から\(O(\log(N))\)に落とせる。これスタックベースじゃなくない?
このアクティビティカウンタの実装はintelのSandy Bridgeより前の内蔵GPUで使用されている。
暗黙的な方法, スタックベース
コンパイラの手助け無しにdivergenceとconvergenceの管理が出来ると嬉しいが、そもそのスタックベースの手法には様々な問題点が存在する。
まずスタックから溢れたエントリを保存するためのキャッシュが必要になるが、Teslaではwarp毎に3KBのキャッシュが必要になる。またバグを含んだプログラムを動かすとスタックが溢れたり逆にアンダーフローを起こしたりする。またコンテキストスイッチに対処するためにスタックのデータを保存し回復する機構が必要になる。
そんな訳でスタックベースはやめといた方がいい。
明示的な方法, スタックレス
Sandy Bridge
Sandy Bridgeではスタックやアクティビティカウンタではなく、スレッド毎にプログラムカウンタ(PC)を持つことでdivergenceとconvergenceを管理している。
スレッド毎のプログラムカウンタ(PTPCs)による管理方法の解説はこっちの方が詳しい。
まずは、スレッド毎に存在するプログラムカウンタ(Per-Thread Program Counters)、略してPTPCsを定義する。これは各スレッドが実行している命令のアドレスを指す。またWarpが持つプログラムカウンタとしてWarp PCを定義する。PTPCsの内、このWarp PCと値が一致するスレッドをアクティブなスレッドとする。
続いてif-else-endif命令を考える。これは条件が偽ならif文のブロックを飛ばしてelseの部分を実行する命令である。真の場合はif文ブロックを実行してelseを飛ばす(多分)。
以下は全てのスレッドでelse部分が実行されるプログラムにおける、Warp PCとPTPCsの挙動となっている。
if文の条件式が評価された際に、全てのスレッドで偽となるためif文のブロックを飛ばしてPTPCsの値が全て3になる。PTPCsの値が全て同一であるので、Warp PCの値も3となり、その後はPCの値がインクリメントされていく。

PTPCs, 全て分岐した場合
次に、if文でdivergenceが発生するプログラムにおけるWarp PCとPTPCsの挙動は以下の通りになる。
if文の条件式が評価されると、T0とT1では真であるのでPCの値は1になり、またT2とT3では偽であるのでPCの値はif文のブロックを飛ばしてelseブロックを指す3となる。この時のWarp PCの値がどうなるかはISAに寄るが、ここではif文のブロックを指す1になるとする。
この時、PTPCsの内でWarp PCと値が一致しているのはT0とT1であるので、T2とT3は非アクティブになり、T0とT1が実行される。その後elseに到達すると、T0とT1はelseブロックを飛ばしてPCは5となるが、この時Warp PCの値とPTPCsにおけるT2とT3の値が一致するため、今度はT0とT1が非アクティブになり、T2とT3が実行される。
そしてelseの最後でPTPCsの全ての値とWarp PCの値が一致することで、全てのスレッドがアクティブになる。
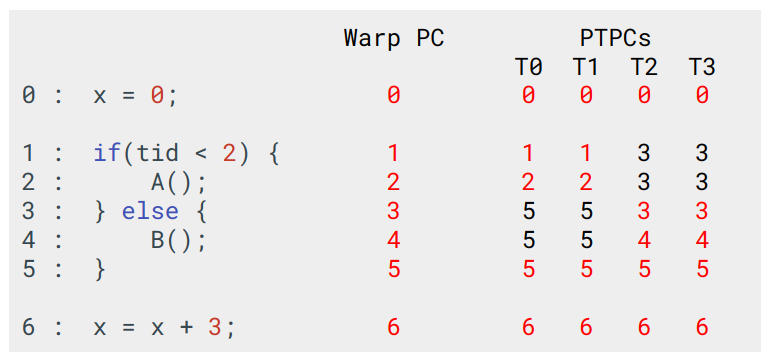
PTPCs, Divergenceが発生した場合
このWarp PCとPTPCsの導入により、Reconvergenceも実現できている。
この実装方法では、ネストの深さ\(N\)として、保存するデータ量をアクティビティカウンタの\(O(\log(N))\)から\(O(1)\)に落とせる。
Lorie-Strong
暗黙的な方法, アクティビティビット
ISAにDivergenceとConvergenceを管理する為の専用の命令無しにSIMTを動かす手法として、高橋氏の手法が存在する。
この手法は各スレッドでPCを持つ。分岐命令が実行された際は、分岐先のアドレスが最も小さいスレッドが優先的に実行される。
暗黙的な方法, スタックレス
もう一つの複数のPCを持つ暗黙的な方法として、Stack-less SIMT reconvergence at low costが提案する手法が存在する。
この手法では、Intelの手法と同じくスレッド毎にPCを持ち、またこれらのPCの値からCommon PCというPCを計算する。
Reconvergence
“We identify reconvergence situations by comparing the values of individual PCs with the selected common PC. Unlike the technique used in Intel GPUs, we operate the comparison continuously, on each cycle. It is thus unnecessary to signal explicitly potential reconvergence points in machine code.”
“(訳) Reconvergenceの検知は各PCとCommon PCとの比較によって行われる。Intel GPUとは異なりこの比較を継続的に各サイクルで行う。これにより、機械語内で潜在的なReconvergenceの地点を明示する必要がなくなる。”
PCsとCommon PCの比較を毎サイクル行うことでif-else-endif命令みたいなのが必要なくなるらしいが、正直よくわからない。
“Branch instructions are handled in a distributed way: each thread computes and update its own PC, as in a MIMD processor. Divergence happens when the local PC of a thread receives a different value than the PC of other threads.”
“(訳) 分岐命令が実行されると、各スレッドはMIMDプロセッサのように自身のPCの値を更新する。Divergenceはこのスレッドが持つPCの値と、他のスレッドのPCが異なる時に発生する。”
これはわかる。PTPCsと同じ。
Traversal Order
アービタはスレッドが持つPC達の値からCommon PCを決定する。Common PCの値は次にFetchする命令のアドレスとなる。このCommon PCは各スレッドが持つPC達から最も小さいものが選ばれる。
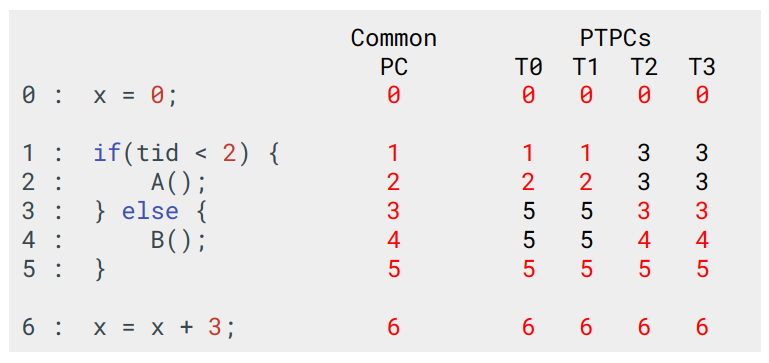
PTPCsの内、最小の値が選択される
これの値の決定方法は、Reconvergenceが発生する地点が、現在実行している地点より大きいアドレスに存在するという仮定に基づいたものとなっている。実際、Collins, Tullsen, Wangの計測によるとこの仮定はSPECintに存在する分岐のうち94%で正しい。
ただ、このCommon PCを各PCの最小値から選ぶ方法は、以下のような関数がプログラムの下で定義されているような場合に非効率となる。
void kernel() {
...
if(c) { // Divergence発生
f();
}
...
}
void f() {
...
}
この例ではif文でDivergenceが発生した際に、f()はkernel()より大きいアドレスに存在しているため、if文で真となりPCがf()を指しているスレッドより先に、偽となったスレッドでif文以降のプログラムが最後まで実行される。その後にf()を指しているスレッドが実行が開始され、returnしてからもう一度if文以降のプログラムがそのスレッドで実行される。これは効率が良いとは言えない。
解決方法としてはプログラムのリンク時に関数は全てkernel()より小さいアドレスに配置するという方法がある。ただ再コンパイルや再リンクが実用的とは限らない。
もっと一般化出来る解決方法としては各スレッド毎にスタックポインタを持つことである。スレッド\(i\)が持つスタックポインタをSP\(_i\)とする。コールスタックがアドレスが減少する方向に伸びると仮定して、最も深く関数コールをしている、最小のSP\(_i\)を持つスレッドが選択される。また全てのスレッドのSP\(_i\)が同じ場合は先の場合と同じく最小のプログラムカウンタを持つスレッドが選ばれる。
この手法では制御フローグラフの走査順序を、最小のPCとSPのスレッドを選ぶとアーキテクチャレベルで決めているため、DivergenceとConvergenceを管理するための命令が必要なくなる。
SIMTYにおける実装
SIMTYとはRISC-VのSIMTプロセッサであり、拡張命令やコンパイラの支援無しにSPMDコードを並列実行できる。すげえ。どうやってDivergenceとConvergenceを実装してるのか気になるよな。
Simtyの解説は先のCaroline Collange先生の資料に載ってるので嬉しい。
まずはPathという概念を定義する。PathはCommon Program Counter(CPC)とマスクから構成される。マスクの各ビットはCPCと同じPCを持つスレッドを意味する。以下の画像では、T1, T2, T4のPCが17を指しているという事を意味する。
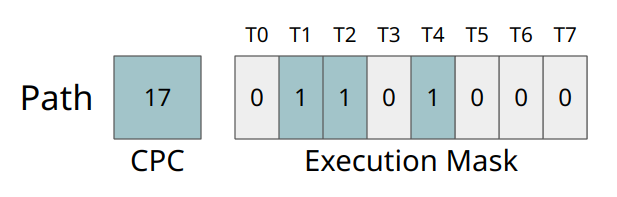
Pathの構造
(GPU architecture part 2: SIMT control flow managementより作成)
そしてPathのリストはPTPCsと同等になる。
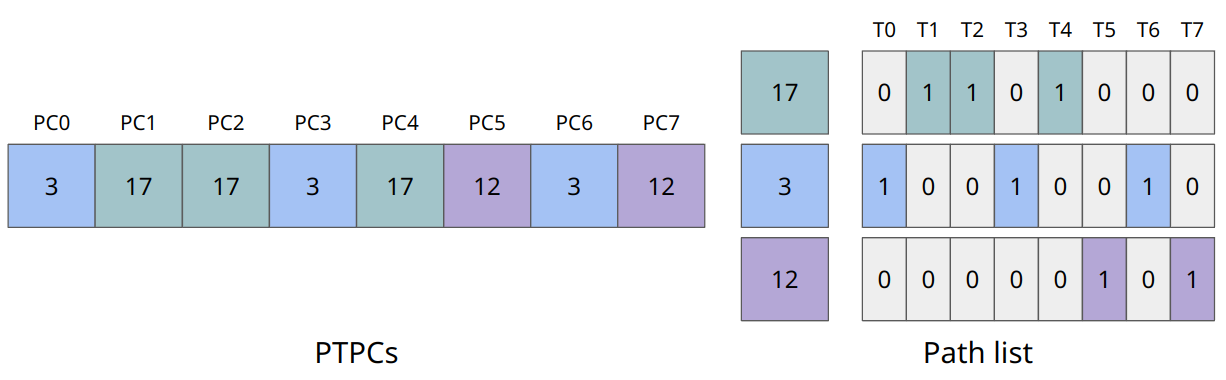
PTPCsとPath listは同等
(GPU architecture part 2: SIMT control flow managementより作成)
プロセッサは、このPathのリストからアクティブなパスを選択し、CPCにある命令アドレスの命令をフェッチする。そして実行マスクにあるスレッドでその命令を実行する。分岐命令を実行しDivergenceが発生した場合、選択されているPathは分岐命令でnot takenのパスとtakenのパスに分割される。
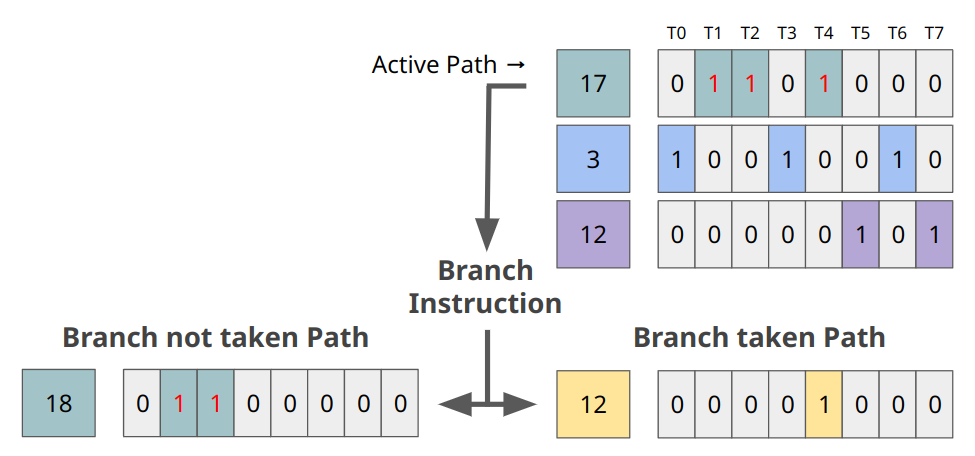
分岐命令時のPath list
(GPU architecture part 2: SIMT control flow managementより作成)
そして新たに生成されたPathはPathのリストに挿入される。Path listはこのようにDivergenceを扱っている。
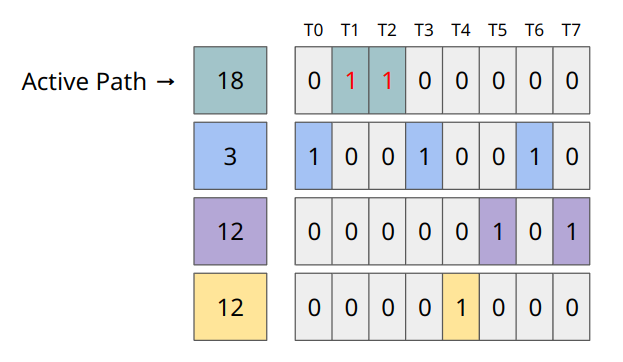
分岐命令後のPath list
(GPU architecture part 2: SIMT control flow managementより作成)
また、PathのリストにおいてCPCが一致するエントリが存在する場合はマージされる。Path listではConvergenceはPath同士のORによって行われる。

Path listにおけるConvergence
(GPU architecture part 2: SIMT control flow managementより作成)
PathにおけるDivergenceとConvergenceが理解できたところで、次の疑問が生じる。
- アクティブなパスをどう選択するか?
- 新たなパスはどこに挿入するか?
- Convergenceの為のCPCの比較はどう行うか?
これらの問題に対する解答によって、制御フローグラフの走査とReconvergenceの戦略が変わってくる。
SIMTYでは、PathはCPCと実行マスクに加えてスタックポインタを持ち、先で挙げた手法と同じくこのスタックポインタを用いて最も深くネストしているPathがアクティブなPathとなる。また全てのPathのスタックポインタが同じ場合は、最も小さいCPCを持つPathがアクティブなPathとなる。
実際にはPathのリストがPathがアクティブになり得る優先度によってソートされ、先頭に存在するPathがアクティブなPathとなる。
またConvergenceを行うための比較は、現在アクティブなPathと次点でアクティブになり得るPathとの間でのみ行われる。
賢いなあ。
SIMTYのアーキテクチャ
実際にRISC-V SIMTの実装がある事だし見てみよう。
SIMTYは10ステージで構成されている。
Fetch steering
Fetch steeringではwarpを選択し、現在アクティブなPathの投機的CPC(おそらくCPCの投機的なアドレスを持つレジスタ)を選択する。warpのスケジューリングはラウンドロビンで行う。そして投機的CPCの値を更新する。現状は値をインクリメントするだけだが、分岐予測器を実装してもよい。
Instruction Fetch / Predecode
Instruction Fetchでは命令を命令キャッシュまたは直接メモリからフェッチする。Predecodeではオペランドに対応するレジスタをチェックし、命令間のデータ依存を確認してレジスタからデータを取り出す。こうしてPredecodeされた命令はWarp毎に1つある命令バッファに格納される。
Scheduler
Schedulerでは命令のオペランドが全て有効になったら命令を発行する。