軽率にGPUを使っていこう、OpenCL入門
はい、Cra2yPierr0tです。GPUを作る前に市販のGPUを触ってみるか、どうやらOpenCLってやつが標準化されてて良さそうだぞ。という動機でOpenCLを書き始めたら思いのほか辛かったし納得のいく入門記事が無かったので備忘録がてらOpenCL入門をここに置いときます。
OpenCLとは
並列プログラミング用のAPI、厳密な定義はwiki読んでね。
https://ja.wikipedia.org/wiki/OpenCL
あとインストールとかは各自で頑張ってください。
OpenCLの思想
OpenCLの思想としてループの関数(カーネル)への展開が挙げられる。例として以下のように1024x1024の画像処理を1個のカーネルで行うのではなく、1024x1024=1,048,576個のカーネルで行うことで処理を高速にする。
古典的な実装
OpenCLでデータ並列性を活用する
OpenCLの計算機システム
OpenCLにとって計算機システムは、単一の制御用のホストと一つ以上のデバイスによって構成されている。そしてデバイスは一つ以上のCompute Unit(CU) からなる。またCUも一つ以上のProcessing Element(PE) から構成される。 メモリシステムもホストメモリとデバイスメモリに大別される。ホストとデバイスを合わせてプラットフォームとも呼ぶ。

ホストとデバイスが何を指すかは覚えておいた方が良い。
ホストとカーネル
OpenCLのプログラムは、GPU上で動くカーネルプログラムとCPU上で動くホストプログラムに分かれている。
カーネルプログラムはGPUで動くプログラムであり、カーネルプログラムが大量に並列実行されることで高速な計算が可能となる。またホストプログラムはCPU上で動くプログラムであり、その主な役割はカーネルプログラムをGPUへ展開する事と、データを転送する事である。
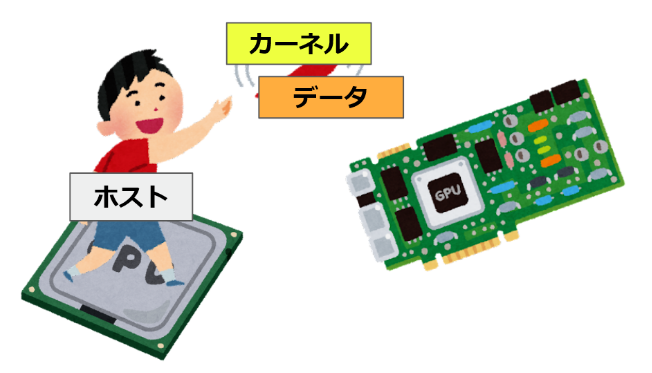
以上の通りOpenCLではホストとカーネルの二種類のプログラムを書く必要があり、特にホストプログラムはやることも多く複雑になりやすい。ホストとカーネルとは何かをきちんと覚えた上で読み進めてほしい。
OpenCLの次元
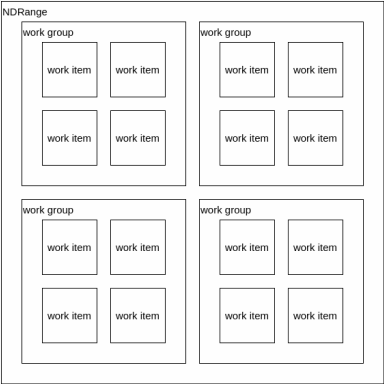
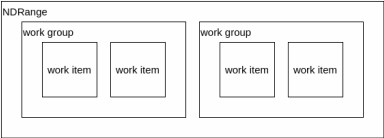
解きたい問題には全て、直線状やキューブ状や平面状のようにある程度の次元性が存在している。 OpenCLでは最大3次元までを指定してカーネルを展開する。また各次元方向のサイズも指定する必要がある。この各次元のサイズをグローバルサイズと呼ぶ。そして各点はワークアイテムによって処理される。
このワークアイテムを纏めたものをワークグループと呼ぶ。1つのワークグループに1つのCUが割り当てられ、ワークグループ内ではローカルメモリの共有と同期が可能である。
ワークグループ内にあるワークアイテムの数を指定することが可能であり、これをローカル(ワークグループ)サイズと呼ぶ。OpenCLランタイムにこのローカルサイズを自動に決定させることも可能だが、大抵の場合最適ではない。
アルゴリズムに最も適した次元を選ぶことが非常に重要である。
OpenCLの基礎知識は以上にとどめ、次は具体例を出しながらホストプログラムの書き方を解説する。
OpenCLホストプログラミング入門
概要
ホストプログラムは基本的に5つのステップに分けられる。
- デバイス, コンテキスト, コマンドキューを定義する
- カーネルをビルドする
- デバイスメモリを確保する
- カーネルの引数を設定する
- キューにメモリとカーネルを転送する
1. デバイス, コンテキスト, コマンドキューを定義する
コンテキスト、キューという概念が出てきた、コンテキストは利用するデバイスをまとめた実行環境(らしい)であるが、OpenCLを使うために必要なオブジェクトというフワッとした解釈で全然問題ない。
コマンドキューに関しては割と重要な概念である。これはコマンド(カーネル及びメモリ等の転送命令)が入るキューであり、デバイスでプログラムを実行するにはこのキューを必ず経由する必要がある。 一つのコマンドキューは一つのデバイスに向かっており、複数のコマンドキューが同じデバイスに向かう事も可能である。この場合、コマンドキュー同士で同期を取る必要は無い。
よってより正確なイメージは以下のようになる。
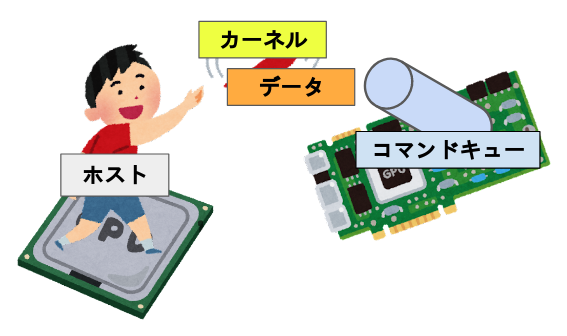
コマンドキューだが、キューに入れた順にデバイスに送るインオーダキューと、入れた順にならないアウト・オブ・オーダーキューが存在する。
主に使う関数はこちら
- 利用可能なプラットフォームを確保:
clGetPlatformIDs()
- デバイスを確保
clGetDeviceIDs()
- コンテキストを作成
clCreateContext()
- コマンドキューを作成
clCreateCommandQueue()
これらの関数を使って必要なものを定義するコードが以下になる。また先頭にclが付いている型や関数はOpenCL APIで定義されているものである。
2. カーネルをビルドする
カーネルプログラムもプログラムであるので、コンパイルして実行形式にしてやる必要がある。OpenCLではカーネルプログラムからプログラムオブジェクトを作成し、そのプログラムオブジェクトをビルドした後カーネルオブジェクトを作成する。
コンパイル方式には、事前にカーネルプログラムをコンパイルするオフラインコンパイルと、ホストプログラムの実行時にコンパイルするオンラインコンパイルの二種類の方式がある。
主に使う関数がこちら
- プログラムオブジェクトを作成
clCreateProgramWithSource()
- プログラムオブジェクトをビルド
clBuildProgram()
- カーネルオブジェクトを作成
clCreateKernel()
これらの関数を使ってカーネルオブジェクトを作成するコードが以下になる。clCreateProgramWithSource()の引数であるkernelsourceはカーネルプログラムを保持している文字列である。
3. デバイスメモリを確保する
データを格納するためにCPUでメモリを確保するのと同様に、GPUのメモリを確保してやる必要がある。
例として、ベクトル加算を行う場合、3つのメモリオブジェクトが必要になる。a, bを入力ベクタとして、cを出力ベクタとする。 先にホスト側でメモリを確保し、適当に初期化する。
次にデバイスメモリを確保し、メモリオブジェクトを得る。関数はclCreateBuffer()を使う。この関数を使ってメモリを確保するコードが以下になる。
clCreateBuffer()の引数を見てみると、入力ベクタにはCL_MEM_READ_ONLYやCL_MEM_COPY_HOST_PTR、ホストメモリへのポインタが指定されていたり、出力ベクタにはCL_MEM_WRITE_ONLYが指定されていたりと、なんとなく何を意図して引数を設定しているか分かるかもしれない。分からなければ後でリファレンスを読めばよい。
4. カーネルの引数を設定する
カーネルには関数のように引数を設定する事が可能である。引数を設定するにはclSetKernelArg()を用いる。
例としてベクトル加算を行う場合、カーネルに渡す必要がある引数は配列a, b, cのアドレスである。第一引数をfloat *a、第二引数をfloat *b、第三引数をfloat *cとして、カーネルに引数を設定するコードが以下になる。
5. キューにメモリとカーネルを転送する
コマンドキューにメモリの書き込み指示、カーネルの展開・実行の指示、メモリの読み出し指示を行う。
主に使う関数がこちら
- デバイスメモリにデータを書き込む、今回はデバイスメモリ確保時に行っているので使わない(疑問点あり)
clEnqueueWriteBuffer()
- カーネルをデバイスに展開し、実行する。後で詳しく扱う
clEnqueueNDRangeKernel()
- カーネルが完了まで待機する
clFinish()
- デバイスメモリからデータを読み出し
clEnqueueReadBuffer()
これらの関数を用いたコードが以下になる。
このclEnqueueNDRangeKernel()がカーネルをどんな形で展開するかを決める非常に重要な関数である。これに関してはカーネルプログラムの書き方を解説する際に詳しく扱う。
ベクトル加算のホストプログラム
以上の1~5を組み合わせて完成させたホストプログラムが以下になる。一番下に計算結果の出力とクリーンアップを追加している。ライブラリとkernelsource、一番下以外は全て前述したコードと同じである。
OpenCLがインストールされている環境下で$ gcc -lOpenCL vadd.cでコンパイルが出来る。
なお、このプログラムはエラー処理を一切行っていないため、テンプレートとして使うことは全く推奨しない。
OpenCLカーネルプログラミング入門
前章のホストプログラムにおけるカーネルプログラムは次のようなものだった。
get_global_id(0)だとか__globalだとか、いくつか見慣れない修飾子や関数があるだろう。これはOpenCLのカーネルプログラミングで用いる独自に拡張されたC言語の追加要素である。なお、この拡張されたC言語は文献によってはOpenCL Languageと呼ばれている。
ちなみに、配列のインデックスを取得しているget_global_id()関数だが、これは直線に並んでいるワークアイテムの位置を取得する関数である。前項のホストプログラムは、ワークアイテムという仮想的なプロセッサを直線状に1024個生成し、それら全てにこのカーネルプログラムを実行させている。実行されているカーネルは同一だが、get_global_id()が返す値がワークアイテムの位置によって異なるため、1024要素のベクトル加算を実現することが出来る。This is SIMD.
以降では、OpenCLによるCの拡張要素とカーネルプログラムの書き方について解説する。
OpenCLカーネルにおけるC言語
拡張されたC言語の概要は以下の通り。
- ISO C99からの派生である
- いくつか制約が存在する:再帰、関数ポインタ、C99の標準ライブラリ関数等々
- C99で定義されるプリプロセッサは利用可能
- 組み込みデータ型
- スカラ型, ベクタ型, ポインタ
- 型変換関数
- 画像用データ型
- 組み込み関数 - 必須
- work-item用関数(そういうのがある) ,math.h, 画像の読み書き
- Relational関数(そういうのがある), Geometric関数, 同期関数
- 組み込み関数 - Optional
- 倍精度, アトミック命令
- 丸めモードの選択, image3d_t surfaceへの書き込み
- 関数修飾子
__kernel修飾子で関数をカーネルコードとして宣言する- カーネルは別のカーネル側の関数を呼べる
- アドレス空間修飾子
__global,__local,__constant,__private等が存在する- カーネル引数となるポインタは必ずアドレス空間修飾子と共に宣言する必要がある
- ワークアイテム関数
get_work_dim(),get_global_id(),get_local_id(),get_group_id()等が存在する
- 同期関数
- Barriers : ワークグループ内の全てのワークアイテムは続行する前にバリア関数を実行しなければならない
- Memory fences : メモリ操作の順序を提供する
OpenCLカーネルのC言語における制約
拡張されたC言語において、いくつか機能が制約されている。
- 関数ポインタは使用できない
- ポインタのポインタはカーネル内では利用できるが、カーネルの引数としては利用できない
- ビットフィールドは利用できない
- 動的配列及び構造体は利用できない
- 再帰は利用できない(まだ)
- double型は予約語だがOpenCL v1.1においてはOptional
OpenCLのメモリモデル
OpenCLのメモリにはいくつか種類が存在する。カーネルプログラミングとは少し離れるが、__globalや__privateの意味を理解するには必須の要素であり、また良い性能を発揮するには理解が必要不可欠の要素であるので、ここで解説する。
- プライベートメモリ
- ワークアイテム毎に持ってるメモリ
- 最も高速で最も小さい: O(10) words/WI(Work-Item)
- ローカルメモリ
- ワークグループ内で共有されるメモリ
- ワークグループ間では共有されない
- O(1~10) Kbytes/Work-Group
- ローバル/定数メモリ
- 全てのワークグループから見えるメモリ
- グローバルメモリ:O(1~10) Gbytes
- 定数メモリ:O(10~100) Kbytes
- ホストメモリ
- CPU側のメモリ
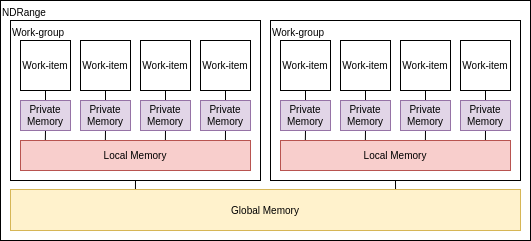
メモリ管理は明示的であり、プログラマはホストメモリ->グローバルメモリ->ローカルメモリの順にデータが移動される事に責任を持つ(逆方向も然り)。 ホストメモリ-グローバルメモリ間はO(1~10) Gbytes/s程度の帯域がある。
例:直列から並列へ
この項では行列乗算を例に、逐次実行のプログラムを並列実行のカーネルに書き換える流れを見せる。
行列乗算:愚直な実装
以下はサイズNの行列A, Bの行列積を計算し、Cに格納するプログラムである。
これをOpenCLカーネルにする。
行列乗算:OpenCLカーネル(1/2)
まずは関数修飾子とアドレス空間修飾子を付ける
行列乗算:OpenCLカーネル(2/2)
そして外側のループを取り除いてワークアイテムの座標をセットする
行列乗算:改善されたOpenCLカーネル
Cの中間変数を置くとパフォーマンスが上がる
次はget_global_id()の正確な使い方や、ワークアイテムを思い通りの形に展開する方法を説明する。
ワークアイテム組み込み関数
上記のOpenCLカーネルでは、get_global_id()といった関数を使用してインデックスを取得していた。この関数はOpenCLにおいてワークアイテム組み込み関数に分類され、カーネルが実行されているCUの位置や、全体のサイズ等を取得するための関数である。OpenCLではこれらの関数から得られた値を元にメモリへアクセスを行う。
OpenCL 1.0におけるワークアイテム組み込み関数は以下の通り
| 関数名 | 説明 |
|---|---|
| get_work_dim | 次元の数を返す |
| get_global_size | 全体のワークアイテムの数を返す |
| get_global_id | グローバルワークアイテムIDを返す |
| get_local_size | ローカルのワークアイテムの数を返す |
| get_local_id | ローカルワークアイテムIDを返す |
| get_num_groups | ワークグループの数を返す |
| get_group_id | ワークグループIDを返す |
カーネルとインデックスの展開
GPUへのカーネルの展開はclEnqueueNDRangeKernelによって行われる。
work_dimでワークアイテムとワークグループの次元を設定し、global_work_sizeで全てのワークアイテムの数を設定する。これはsize_t型の配列を引数に取り、{8, 8}で64個、{8}で8個のワークアイテムが生成される。local_work_sizeではワークグループ内におけるワークアイテムの数を設定し、設定方法はglobal_work_sizeと同一である。
clEnqueueNDRangeKernelとワークアイテム組み込み関数の対応を図式すると以下の通りになる。
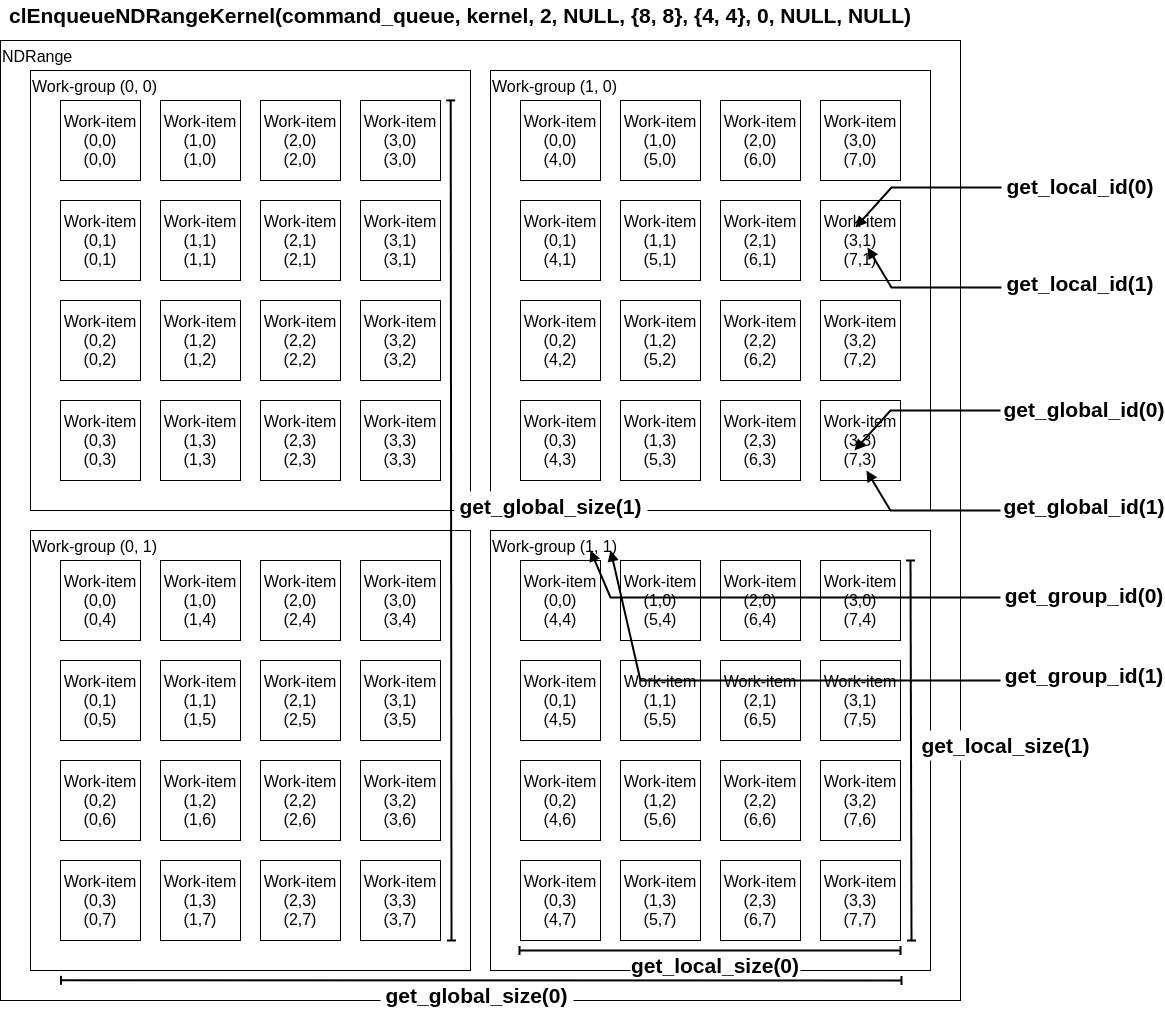
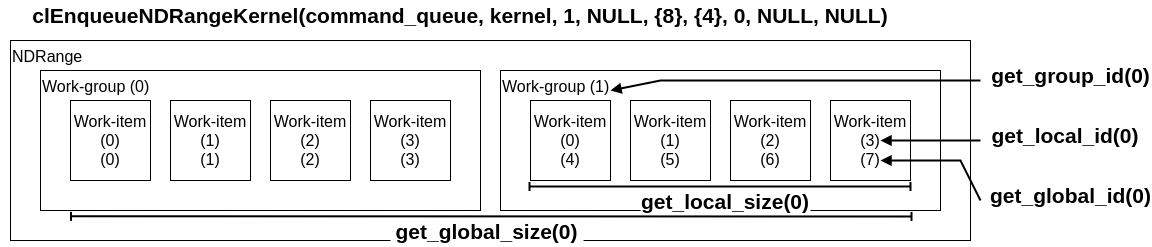
性能を出すためには問題に最も適したwork_dimとglobal_size、local_sizeを選ぶことが重要である。
OpenCLにおけるデータ型
ホストプログラムではcl_uintやcl_memのような独自の型が使われていた。カーネルでも同様に、OpenCLによっていくつか型が追加されている。
スカラーデータ型
| カーネルにおける型 | ホストにおける型 | 説明 |
|---|---|---|
| bool | n/a | true又はfalseが格納される。trueは1として解釈され、falseは0として解釈される。 |
| char | cl_char | 符号付き8bit整数 |
| unsigned char, uchar | cl_uchar | 符号なし8bit整数 |
| short | cl_short | 符号付き16bit整数 |
| unsigned short, ushort | cl_ushort | 符号なし16bit整数 |
| int | cl_int | 符号付き32bit整数 |
| unsigned int, uint | cl_uint | 符号なし32bit整数 |
| long | cl_long | 符号付き64bit整数 |
| unsigned long, ulong | cl_ulong | 符号なし64bit整数 |
| float | cl_float | 単精度浮動小数点数 |
| half | cl_half | 半精度浮動小数点数 |
| size_t | n/a | sizeof演算子が返す符号なし整数。clGetDeviceInfoにおけるCL_DEVICE_ADDRESS_BITSが32bitで定義されていれば32bitとなり、64bitで定義されていれば64bitとなる。 |
| ptrdiff_t | n/a | 2つのアドレスの減算結果が返す符号付き整数。clGetDeviceInfoにおけるCL_DEVICE_ADDRESS_BITSが32bitで定義されていれば32bitとなり、64bitで定義されていれば64bitとなる。 |
| intptr_t | n/a | 符号付き整数。voidへのポインタをこの型に変換とその逆が可能であり、またその結果は元のポインタと等しくなる。 |
| uintptr_t | n/a | 符号なし整数。voidへのポインタをこの型に変換とその逆が可能であり、またその結果は元のポインタと等しくなる |
| void | void |
ベクトルデータ型
ベクトルデータ型で値をまとめる事が出来る。n に指定する値によってサイズが変わり、\(n\)には2, 4, 8, 16のいずれかを指定出来る。
| カーネルにおける型 | ホストにおける型 | 説明 |
|---|---|---|
| charn | cl_charn | 符号付き8bit整数ベクトル |
| ucharn | cl_ucharn | 符号なし8bit整数ベクトル |
| shortn | cl_shortn | 符号付き16bit整数ベクトル |
| ushortn | cl_ushortn | 符号なし16bit整数ベクトル |
| intn | cl_intn | 符号付き32bit整数ベクトル |
| uintn | cl_uintn | 符号なし32bit整数ベクトル |
| longn | cl_longn | 符号付き64bit整数ベクトル |
| ulongn | cl_ulongn | 符号なし64bit整数ベクトル |
| floatn | cl_floatn | 単精度浮動小数点ベクトル |
一般行列ベクトル積を書いてみよう
習うより慣れろ、ということで線形代数演算APIであるBLAS(そういうのがある)のSGEMV、単精度行列-ベクトル積をOpenCLで実装してみよう。
SGEMV
単精度行列-ベクトル積SGEMVは以下の演算を行う。
y = αAx + βy
| 変数名 | 説明 |
|---|---|
| α | スカラー |
| A | 行列 |
| x | ベクトル |
| β | スカラー |
| y | ベクトル |
なお、ベクトルは全て列ベクトルとして扱われる。また行列の行サイズをN, 列サイズをMとする。
とりあえずカーネルプログラムを書く
このSGEMVをどうにか並列に実行したい。パッと思いつくのはワークアイテムを一次元に展開して\(A\)の行毎に実行してやる方法だろう。
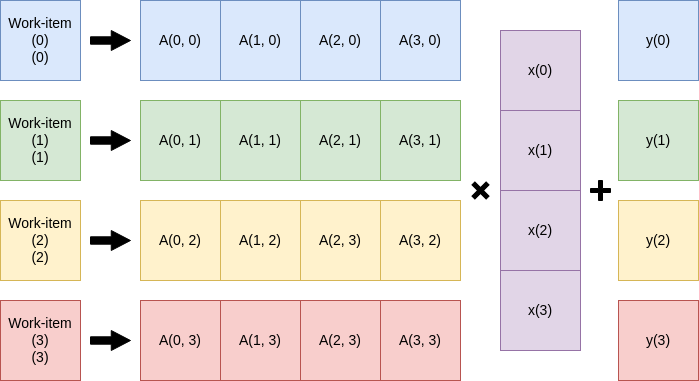
性能が出るかは知らないがとりあえず実装してみる。
こんな感じだろうか、解説すると9行目でワークアイテムの位置を取得し、それを\(y\)のインデックスとする。次にベクトルのサイズ分(この場合N)だけ乗算を回す。OpenCLはカーネルに2次元配列をそのまま渡すことが出来ないため、Aのインデックスは1次元配列を2次元配列として扱ったものを使っている。
ホストプログラムを書く
カーネルプログラムが書けたら次はそれらを展開するホストプログラムを書いてやる必要がある。忘れない内にclEnqueueNDRangeKernel()を真っ先に書く。
行列の列サイズを仮に1024としてる。また今回は、第6引数であるlocal_work_sizeをNULLに設定し、OpenCLランタイムにワークグループが持つワークアイテムの数の設定を任せている。
他の部分はOpenCLホストプログラミング入門の流れに沿って書いていく。
1. デバイス, コンテキスト, コマンドキューを定義する
OpenCLホストプログラミング入門と特に変更はない。
2. カーネルをビルドする
カーネルオブジェクトの変数名とclCreateKernel()の引数をsgemvに変更した。
3. デバイスメモリを確保する
ベクトル加算と異なり、行列ベクトル積であるのでAに関するメモリの確保の部分を追加する。
上記では行列の列サイズを1024としており、もう細かいことを考えるのが面倒なので行列サイズを1024x1024とする。
まずはホストメモリを確保する。 次に適当に初期化する。
デバイスメモリを確保する。d_y_outは計算結果を格納するためのメモリである。
4. カーネルの引数を設定する
引数がN, \(A, x, y, \alpha, \beta\), y_outと増えているので追加する。
5. キューにメモリとカーネルを転送する
clEnqueueNDRangeKernel()と結果の読み出し部分に変更を加える。
SGEMVのホストプログラム
以上の1~5を組み合わせたホストプログラムが以下の通り、クリーンアップと実行時間、計算結果の計測部分を追加しているが、それ以外は全く変更を加えていない。
このプログラムを適当な名前で保存し、OpenCLランタイムがインストールされている環境下でgcc -lOpenCL filename.cとするとコンパイルできる。
ここまでの流れを正しく理解できていれば、簡単な処理に対してGPUという選択肢を考慮する事が可能になるだろう。
カーネルの最適化
カーネルに工夫を加えるとよりGPUのポテンシャルを引き出し、性能の良いプログラムを書くことが出来る。
本章では\(C = A \times B\)の行列乗算を例に、どうすればより良いカーネルを書けるか解説する。なお、ここの知識はほぼHands on OpenCLの受け売りであるため、最適化に関してオススメの資料などがあれば是非教えてほしい。
最適化前のカーネル
以下は、CがサイズNxNの行列だとして、NxN個のワークアイテムを生成する事を前提にしたカーネルである。
ワークアイテムとワークグループ管理のオーバヘッド
ワークアイテムとワークグループの管理には大きなオーバーヘッドが存在する。つまり仮にN=1024だとして、NxN=1024x1024=1048576個のワークアイテムをGPUに管理させるのは得策ではない。
そこでワークアイテムを直線状に配置し、各ワークアイテムにはCの行ごとの計算をさせる。一度に計算する量が減るかもしれないが、ワークアイテムの数がNに削減できる。
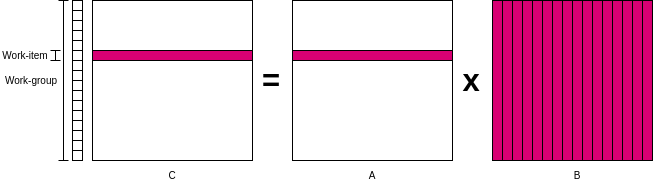 ついでに今後の最適化を見越して、
ついでに今後の最適化を見越して、clEnqueueNDRangeKernel()をいじってワークグループが持つワークアイテムの数(local_work_size)を64に設定しておく。この場合、仮にN=1024だと16個のワークグループで実行できる。
以上の最適化を加えたカーネルが以下になる。
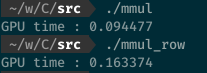
ただ筆者の環境ではこの最適化手法は効果が無かった。むしろ遅くなった。
プライベートメモリの利用
前回のカーネルを引き続き最適化する。Aの行に注目してほしい、各ワークアイテムにおいてAの行を使いまわす事が出来るのは、行列乗算の計算方法からして当然だろう。このような何度も使いまわすデータはPEの近くに置いておくのが得策である。
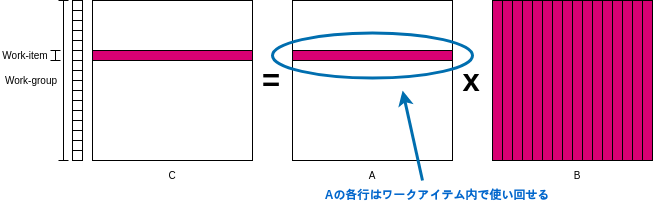
だが、先程最適化を加えたカーネルを見てみると、引数のAに__globalが付いていることからもわかる通り、Aの値をわざわざグローバルメモリから取りに行っている。これは非常に無駄である。
そこでAの一列分だけグローバルメモリからプライベートメモリに移してやる。その修正を加えたカーネルが以下の通り。
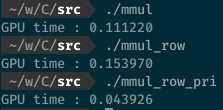
この最適化によって、最適化前の約3倍の計算速度を達成できた。
更に速く!ローカルメモリの利用
Aの行をワークアイテム内で再利用できる事は話したが、先程最適化を加えたカーネルを見てみるとBの列を取得する際に、まだグローバルメモリにアクセスしている。
これもプライベートメモリに入れてしまいたいが、カーネルの最初から最後まで不変なAの行番号と異なり、計算に用いるBの列番号はワークアイテムの一番外側のfor文で変わってしまう。
だが、内側のfor文においてBの行番号は不変であるので、ある程度Bの列も使い回せる。そこでローカルメモリにBの列を置いておき、グローバルメモリより近く、そしてワークグループ内の全てのワークアイテムがアクセス出来るようにする。
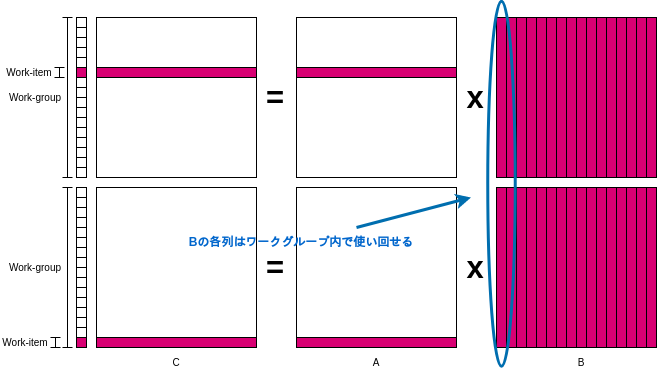
ローカルメモリを使うようにしたカーネルが以下の通り。ローカルメモリにBwrkを確保し、ワークグループ内のワークアイテム達が並行してBwrkにBの一列を格納している。
合間合間にbarrier(CLK_LOCAL_MEM_FENCE)が挿入されているが、これはバリア命令と呼び、ワークグループ内の全てのワークアイテムがこのバリア命令を実行するまで次の命令を実行させない働きがある。引数にCLK_LOCAL_MEM_FENCEを指定することでローカルメモリまでに対するアクセスが確実に完了させてから停止する。
なお大して速くならない。
真の速さを手に入れたくば
本章ではメモリ階層だけに注目して最適化を行ってきたが、実際には多くの行列乗算を高速に行うためのテクニックが存在している。
たとえば、ワークアイテムの個数は計算機のベクトル幅の倍数でなければならない。これはAMDではwavefront、NVIDIAではwarp、CPUではSIMDレーン数と呼ばれている。
データの再利用を最適化するためにはブロック化の技術が必要になる。行列をプライベートメモリにちょうど収まるようにタイルに分解したり、タイルをローカルメモリにコピーしたり、タイル間で乗算を行う技術である。
おわりに
GPUはパワーです、軽率にGPUを使ってGPUの需要を増やしましょう。次はOpenCLデバイス自作をやりたい。あと感想、意見、コメントがあれば呟くなりなんなりしてくれると泣いて喜びます。
おすすめbook [増補改訂]GPUを支える技術 ――超並列ハードウェアの快進撃[技術基礎] WEB+DB PRESS plus Hisa Ando著