Implementing Hardware Extensions for Multicore RISC-V GPUsを読む
RISC-V GPUへのハードウェア拡張の実装に関する論文の内容をサマライズしていく。
出典:https://carrv.github.io/2022/
経緯
ちょうど本日ISCAの併設CARRVでRISC-VのGPU拡張の論文が出ているので、サマライズして教えてください(笑)。https://t.co/C2T8McuydM
— Masayuki@FPGA開発日記 (@dev_msyksphinz) June 20, 2022
Implementing Hardware Extensions for Multicore RISC-V GPUs https://t.co/PJa9LkvEzh
ベースとなってる Vortex: OpenCL Compatible RISC-V GPGPUの Micro 2021でのチュートリアルと MICRO 2021発表ペーパーです https://t.co/KnyNS7mMF6
— OGAWA, Tadashi (@ogawa_tter) June 20, 2022
1stの博士課程の学生とラスト:Hyesoon Kim教授は一緒です、研究室 https://t.co/5el0C4MQGv
では、よろしくお願いします。
やるぞい
要約
内容:RISC-VベースのGPUへのハードウェア拡張の効果的な実装方法の提案
マイクロアーキテクチャの方針
- アクセラレータは各コアの内側に実装するのが望ましい
- アクセラレータが頻繁に使われない場合は内側に置いても意味がない
- アプリケーションの中身をよく見極めて頻繁に呼ばれるであろうアクセラレータを決める
- コア外部のアクセラレータにはキャッシュを付けると良い
- キャッシュを付けてレイテンシが改善されるならコア内部にアクセラレータを置いても良い場合がある
- アクセラレータのコンフィグにはCSRを使うと良い
- コアの外部にアクセラレータを置く場合、各コアにアクセラレータとの通信管理用のローカルエージェントを置く場合がある
- 同様のケースでアクセラレータがGPUのどのコアと通信するかを決めるマルチプレクサ/デマルチプレクサを使う場合がある
ISAの方針
- 自作の拡張命令で使えるオペコードは4つ
- 3つの引数が使えるR4フォーマットの利用を優先すべき
- 1命令が取る引数を増やしたい場合は隣接するビットフィールドをマージするのが最も望ましい
- 次点でファンクションビットを引数のフィールドとして扱う方法もある
- 命令の総数が減るのでオススメはしない
- CSRをアクセラレータの引数入れとして扱うのは推奨できない
- アクセラレータの利用に2命令必要になってIPCが下がる
- 追加した命令はコンパイラにも対応させた方が良い
- ハードウェアパフォーマンスカウンタ(そういうのがある)は枯渇しがちなのでクラス分けして使うと良い
感想:おもしろかった
以下翻訳
1. Introduction
近年、RISC-V ISAをベースにしたGPUが発表され始めている。
https://ieeexplore.ieee.org/document/8918510
https://ieeexplore.ieee.org/document/6942056
https://carrv.github.io/2017/papers/collange-simty-carrv2017.pdf
これらのGPUはRISC-Vの整数乗除算や浮動小数点数演算などの標準拡張(MとかFとかDとか)を実装しているが、これに画像解析やグラフ解析、機械学習用の専用ハードウェアを追加するとなると標準拡張だけでは不十分であり、非標準の拡張を実装する必要がある。
しかし、専用ハード向けのISAとレジスタをRISC-Vと互換性を保ったまま実装したり、専用ハードをプロセッサに接続する手法は、未だに確立していない。
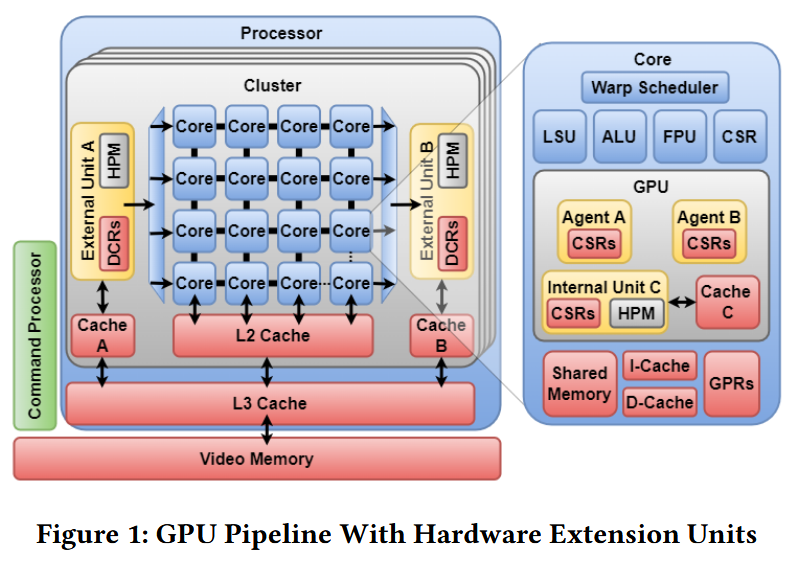
GPUと専用ハードA, B, Cの位置関係をFigure.1に示している。専用ハードの位置としてコアの上流にあるAや下流にあるB、Cのような他の標準拡張と似たように各コアの内側に存在している場合などが考えられる。
この論文ではRISC-VベースのGPUに対して、専用ハードウェア用の拡張を実装する一般化された手法を紹介している。この論文で紹介されている技術はなんとシングルコアまたはマルチコアのCPUにも適用することが可能とのこと。
提案手法はISAとマイクロアーキテクチャの両方を取り扱い、加えてオンボードで専用ハードを持つ計算機のためのハードウェアパフォーマンスカウンタ(そういうのがある)の一般的な手法の提供する。
この論文のkey contributionsは以下の通り
- デザインの設計要件とGPUとの相互作用の観点からのGPU拡張構成の提案
- RISC-VベースのGPUに対する一般的な拡張機能の実装手法の紹介
- オンボードで専用ハードを持つ計算機に対するハードウェアパフォーマンスカウンタの一般的な手法の提供
- RISC-VベースであるVortex GPUへの提案手法の適用
2. BACKGROUND
2.1 Processor Hardware Extensions
プロセッサは誕生したその頃から専用ハードが実装されてきており、その操作はISA拡張を介して行われてきた。GPUも計算を加速するために同様の手法を取ってきた。
2.1.1 CPU Hardware Extensions
CPUのハードウェア拡張は色々ある。FPUはもちろん暗号とか乱数生成とかNNとか。
2.1.2 GPU Hardware Extensions
GPUのハードウェア拡張は大部分をグラフィック用アクセラレータが占めており、ラスタライザとかテッセレーションとか色々ある。またFPU共に機械学習用のハードウェアも実装されている。
2.2 RISC-V ISA Extension
2.2.2 User-Defined Extensions
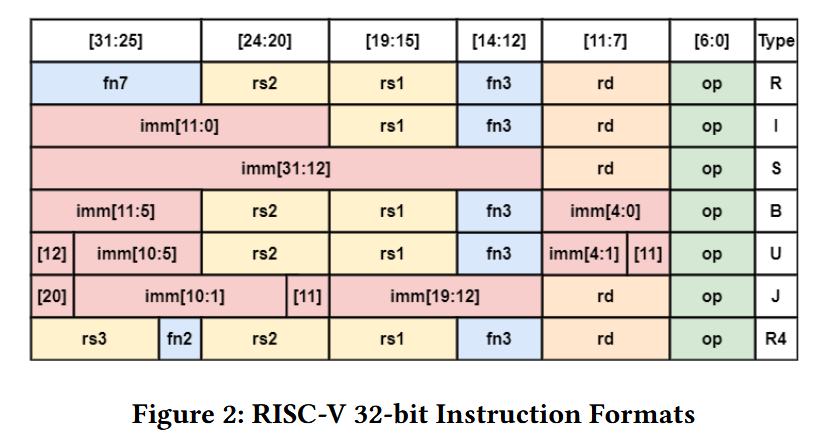
RISC-Vではユーザー定義用のオペコードに0x0B, 0x2B, 0x5B, 0x7Bが使える。命令フォーマットはFigure.2に沿うが、RISC-Vの整数命令のオペランドは最大2個、浮動小数点数命令だと最大3個であり、これだと十分でない場合がある。
2.2.3 Hardware Performance Monitoring Counters
性能の統計を評価するためにはハードウェアパフォーマンスカウンタ(そういうのがある)は必要不可欠であり、RISC-VではCSRのアドレス0xB00-0xB1F及び0xB80-0xB9FがHPM counter用に確保されている。
2.3 Vortex GPU Framework
VortexはRISC-VベースのSIMT GPUである。デザインはFPGAに最適化されており、最高250MHzで動作し、64コア1024スレッドとなっている。
2.3.1 Vortex ISA
Vortexには標準拡張に加え、wspawn, tmc, split, join, barの5つのSIMT実行モデル用とtexのテクスチャサンプリングの高速化用の命令が追加されている。
2.3.2 Software Stack
VortexはOpenCLをサポートしている。
2.3.3 Hardware Stack
Vortexのコアは5段パイプラインでFPUに加えてテクスチャ用アクセラレータを搭載している。
VortexはOpenCLコンパチらしいですね…おっとここに良質なOpenCL入門記事が。
[https://cra2ypierr0t.hatenablog.jp/entry/2022/06/22/032512:embed:cite]
3 A TOPOLOGY OF HARDWARE EXTENSIONS
普通のGPUにはハードウェア拡張として、浮動小数点数演算器(FPU)、固定小数点数積和演算器(IMADD)、SHA256変換器(sha256sum)、行列乗算器(MatMul)、ソフトウェアプリフェッチ(Prefetch)、頂点フェッチエンジン(VFetch)、ラスタライザ(Raster)、グラッフィクス属性補完(Interp)、テクスチャサンプリング(Tex)、アルファブレンド(Blend)がある。これらのプロセッサから見た分類をTable.1に示した。
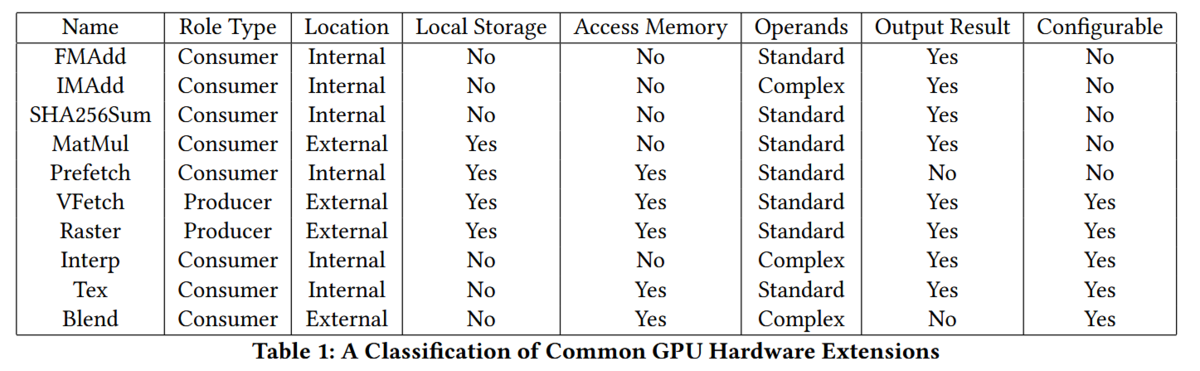
各ハードウェア拡張のオペランドをTable.2に示した。

3.1 Producer vs Consumer Extensions
ハードウェア拡張はプロセッサコアからデータを受け取るコンシューマと、プロセッサコアにデータを与えるプロデューサに分けられる。拡張の大多数はコンシューマであり、基本的にプロセッサコアにトリガされて動作する。また、プロデューサの拡張は常にコアにデータを提供し、処理すべきデータが無い場合はその旨をコアに伝える必要がある。
3.2 Internal vs External Extensions
ハードウェア拡張はその位置によっても分類される。ハードウェア拡張は回路面積や帯域の成約に応じて、コアの外側または内側に配置される。基本的に、ハードウェア拡張は内側に配置されるのが望ましい。これにはいくつかの利点が存在しており、1) ハードウェアをコア間で共有しないため、ハードウェア拡張-コア間の帯域幅を最大化出来る。これはハードウェア拡張がメモリアクセスを行わない場合に特に有効となる。 2) コア内の既存のインターフェースと統合出来るため、デザインの複雑性を低減出来る。内部への拡張の主な欠点は、各コアに新たな回路が追加されるため回路面積が増大する事が挙げられる。
ハードウェア拡張をどこに配置するかを決定する効果的な手法は、アプリケーションに必要な帯域幅を決める事である。
例えばアルファブレンド(Blend)は内側と外側どちらでも置くことは可能だが、ピクセルシェーダプログラムは繰り返される数百から数千の命令の最後の一回にしかこの命令を呼ばないため、アルファブレンド用のハードを内側に置いたところで無視できる程度の改善しか得られない。一方でテクスチャサンプリング(Tex)のハードウェアは内側に置くのが望ましい、これはこの命令がピクセルシェーダプログラムの各繰り返しで何度も呼ばれるためである。
3.3 Needing local storage
拡張にもよるが、行列乗算(MatMul)のように一時的にデータを保存するためのストレージが必要な場合がある。この実装は広いベクトルレジスタを持たないスカラプロセッサの場合によく合っている。(わからん)
3.4 Accessing Memory
メモリアクセスを必要とするハードウェア拡張は、コアの外側に位置する事が多い。これは主にメモリレイテンシが原因であり、コアからのアクセスを保留にする要求をキューに入れる必要があるからである。このようなハードウェア拡張は一般的にメモリ律速になり、これはハードウェアをコアの近くに置くことのメリットを低減させる。実際にはこの様なハードウェアはメモリレイテンシを減らす為にプライベートキャッシュと一体化される。テクスチャサンプラはメモリアクセスを行うにも関わらずコアの内側に存在している。これはリードオンリーのキャッシュメモリが付いており、メモリレイテンシが軽減されているためである。
3.5 Complex Operands
拡張命令を実装する上で重要な要素の一つが、入力をアクセラレータにどう与えるか、である。 拡張命令がソースオペランドをRISC-V ISAで定義されている以上に必要な場合(この場合3)、その命令は複雑なオペランド(Complex Operands)に分類される。複雑なオペランドをどう対処するかは性能へ影響を与える。この問題に対する戦略は後に説明する。
3.6 Configurable Extensions
ハードウェア拡張には使う前に動作や定数のコンフィグレーションを必要とするものが存在する。RISC-Vにおいてハードウェアをコンフィグレーションを際に最も推奨される方法が、Control status register(CSR)を使うことである。RISC-Vでは読み書き可能な512スロットのCSRと読み出し限定の192個のCSRが拡張の為に確保されている。
4. RISC-V ISA EXTENSION
ここではRISC-Vのための命令エンコーディングの拡張方法を解説する。
4.1 Instruction Encoding
新たな命令のために、RISC-Vでは0x0B, 0x2B, 0x5B, 0x7Bの4つのオペコードが用意されている。利用可能なオペコードは4つであり、将来の拡張のために可能な限り再利用することを考えると、主な難題は命令フォーマットを決める事となる。主に使われるのはfigure 3におけるRとR4の命令フォーマットである。
4.1.1 R format
Rフォーマットは最も柔軟なフォーマットであり、C=f(A, B) の形式の命令なら全てこれでよく、またfunc3とfunc7のフィールドによって1024通りの命令が定義可能だからである。
4.1.2 R4 format
R4フォーマットはオペランドの数が多い場合に最も良いフォーマットであり、3つのオペランドを持つことが可能である。ただその欠点として、func3とfunc2の32通りの命令しか定義出来ない。
実際には命令フォーマットはR4の実装が優先され、最低でも2つのオペコードで使われる。これはGPUのハードウェア拡張では2つ以上のオペランドが要求される事が多いからである。
4.2 Operands Extension
オペランドを3つ以上要求するハードウェア拡張において、パラメータをどのように渡すかはその性能に大きな影響を与える。本論文では3つ以上のオペランドの扱い方を3種類に分けて検証した。
4.2.1 Inputs Merging
最も効果的な方法は、Figure 5のように単純に複数のビットフィールドをマージする方法である。これはBlendのように引数の数が固定されず、複数のオペランドとなる場合と、複数のオペランドが連結して一つのオペランドになる場合に非常に効果的となる。(なぜ?)
4.2.2 Functions Merging
引数をマージ出来ない場合、次に取れる選択はFigure 6のようにファンクションビットをまとめて追加のレジスタとする方法である。これはR3フォーマット(謎)では2つのオペランドを追加でき、R4フォーマットでは1つのオペランドを追加することが可能である。これには2の欠点があり、1) これはファンクションビットをオペランドに使うため、トータルの命令数を減らしてしまう。2) ソースオペランドの数を増やすと、追加のレジスタを読み込むことでバックエンドが複雑になるため、既存のパイプラインでサポートされているレジスタファイルへの依存性が生まれる。
4.2.3 Control Status Registers
最後の手段としてCSRを経由してオペランドを与える方法があるが、この方法は実行をCSR操作命令と普通の命令の2つに分ける事になるため全く効率的ではない。まずCSR命令はパイプラインをストールさせ、拡張命令の呼び出しの度にCSR操作命令も必要になるためIPCに影響を与える。
4.3 Software Support
ソフトウェアレイヤにおいて、アプリケーションは新たに追加された命令を実行する必要がある。最も優先される方法はコンパイラへの新たな命令の実装である。この方法の主な利点が高レベルのコード変換が可能となることである(謎)。その他の利点としてアセンブラと逆アセンブラによるデバッグへの恩恵が挙げられる。 コンパイラへの追加の代替案としてはListing 1のようなバイトコードをラップした組み込み関数がある。

5. IMPLEMENTING EXTERNAL EXTENSIONS
外部にハードウェア拡張を実装することは、複数のプロセッサによってそのハードウェアが共有される点において熟考に値する。
5.1 Local Agents
ローカルエージェントはコア内にある軽量のモジュールであり、外部のハードウェアとの通信を管理する。ローカルエージェントは発行された命令を外部のハードウェアで実行できるようにスケジューリングし、必要であればコア毎のローカルストレージの管理も行う。
Figure 1で外部のハードウェアA, BのためのローカルエージェントA, Bが示されている。
5.2 Arbitration
外部のハードウェアに対するアクセスの調停は柔軟なマルチプレクサ/デマルチプレクサによって行われる。どちらを用いるかはハードウェア拡張がコンシューマかプロデューサかによるが、その柔軟性はデータの適切なハンドシェイクの役に立つ。Figure 1ではAでデマルチプレクサが使われ、Bでマルチプレクサが使われているのが示されている。
6. HARDWARE PERFORMANCE COUNTERS
ハードウェアパフォーマンスカウンタ(そういうのがある)はハードウェアの性能の測定とデバッグに必要不可欠である。RISC-V ISAでは32個のカウンタしか定義されておらず、またそのうち3つは予約されている。 ハードウェア拡張を計測するためのハードウェアパフォーマンスカウンタを実装する際、これは非常に枯渇しやすい。ハードウェア拡張が無い場合でさえも、通常のパイプラインを構築するだけでかなりのハードウェアパフォーマンスカウンタを消費する。我々は単純なデータキャッシュの計測でさえ、最低でも半分のカウンタを消費する事に気づいた。
6.1 Hardware Implementation
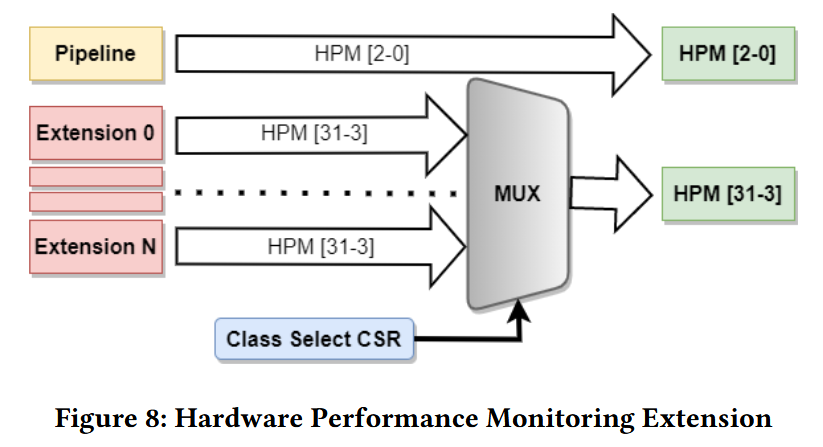
カウンタの上限の回避策として、カウンタをカテゴリ分けする方法が挙げられる。コンポーネントに基づくカテゴリ分けがオススメである。具体的にはプロセッサパイプラインをクラス0、命令キャッシュをクラス1、データキャッシュをクラス2とする。この実装ではクラスの選択に非標準のCSRを用いることが出来る。Figure 8にマルチプレクサを用いた単純な実装を示した。なお、HPMのスロット0, 1, 2は予約されているためマルチプレクサからは除外している。
6.2 Software Support
ハードウェアパフォーマンスカウンタからのデータを得る最も自然な方法は、カウンタの内容をメモリにダンプする方法である。ホストCPUが読むためのメモリ空間を予約して実装する。最長のキャプチャを得るために、プログラム終了時にカウンタをフラッシュするのが好ましい。これはmain関数からリターンした後の_exit()関数内でダンプを実行する形で実装する。
7. SAMPLE IMPLEMENTATION
この項では我々がVortex GPUに対して行った固定小数点数積和演算について解説する。固定小数点演算はグラフィックスにおいて浮動小数点数演算の近似によく用いられる。
7.1 ISA Encoding
固定小数点数積和演算は、以下のように定義される。
\[f(a, b, c, F) = ((a * b) >> F) + c\]この命令のフォーマットは3オペランドのR4フォーマットを用いている。また、この演算における定数Fは多くの場合8, 16, 24を取るため、R4フォーマットのfunc2のフィールドが0->0, 1->8, 2->16, 3->24としている。 これはfunc2を3ビットシフトで得られる。 このエンコーディングによって、同じハードウェアで整数の積和演算を行うことが可能になり、拡張の価値を高めることが出来る。
7.2 Microarchitecture
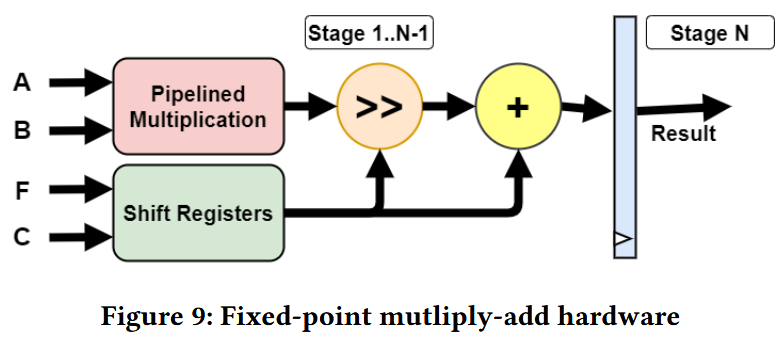
Figure 9はハードウェア拡張のマイクロアーキテクチャであり、これはAとBの乗算を複数サイクルに渡って行うパイプライン化された乗算器と、FとCを同期しながら加算器とシフタに渡すシフトレジスタから構成される。
7.3 Evaluation
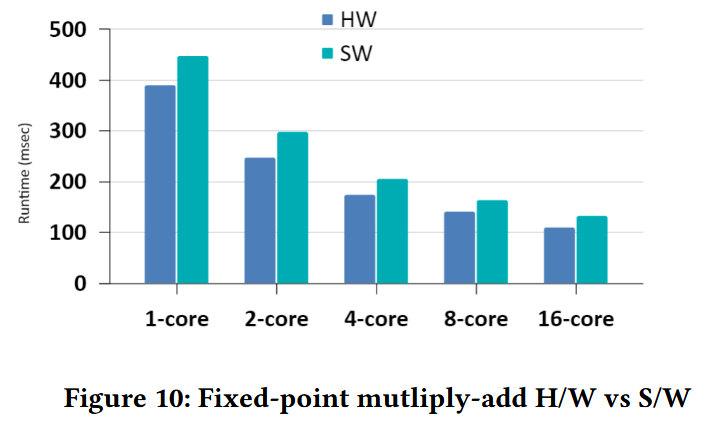
Figure 10は固定小数点数演算命令を複数回呼び出すプログラムの、ハードウェア拡張とソフトウェア実装の比較である。なと200MHzのArria 10 FPGAで動作している。 結果を見ると、ソフトウェアとハードウェア両方でコアの数に対してよくスケールしている。我々のハードウェア拡張はソフトウェア実装に対して17-20%程優れているが、これは大きな改善という程でもない。これはソースオペランドがメモリから値を読んでいるため、プログラム内でオーバヘッドが生じているのが原因である。
8. RELATED WORK
Austinの論文ではVortex GPUにRISC-Vの暗号拡張を追加しており、筆者は公式のRISC-Vの暗号拡張を実装に用いた。彼らはハードウェアを各コアの内部に実装し、AES256とSHA256に対してそれぞれ6.6倍と1.6倍の高速化が得られた。
Kuoの論文では暗号におけるガロア体演算の拡張を提案し、4つの非標準拡張命令を実装した。ハードウェアは各コアの実行ユニットの内部に追加され、ソフトウェア実装に比べ77%のクロックサイクルの削減が達成された。
9. CONCLUSION
本論文ではRISC-Vプロセッサに対してハードウェア拡張を行う上での様々な難題に対して議論した。我々は性能とコストに基づいて様々な選択肢を提案し、比較した。 またRISC-V ISAは、拡張命令のサポート、非標準のCSR、ハードウェアパフォーマンスカウンタ等のハードウェア拡張を行うための豊富な機能が用意されている。 デザインのコストと利益を理解した上で、それらの機能を有効に活用することはアーキテクトの腕に掛かっている。