
コンピュータアーキテクチャ入門
さあ始めましょう。
プログラムが動く流れ
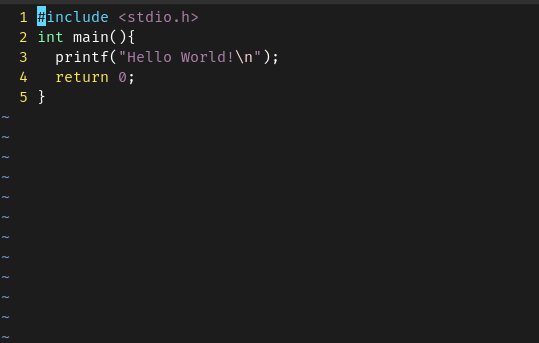
CPUはプログラムをどのように実行しているのでしょうか?CPUはプログラムを動かす物体ですので、一度ここで学んでおきましょう。

CPUはプログラムをそのまま実行している訳ではありません。
現代では、プログラムはコンパイラというソフトウェアによってアセンブリという中間言語に変換され、そのアセンブリはアセンブラというソフトウェアによって011010101...のようなバイナリに変換されます。
CPUとってプログラムはこのバイナリになって初めて実行可能な形式になるというわけです。
- プログラム
- アセンブリ
- バイナリ
命令セットアーキテクチャ
先程、プログラムはバイナリに変換されて初めてCPUが実行可能な形になると言いましたね、プログラミング言語がこの世に沢山あるのと同じように、実は変換後のバイナリもこの世にはいくつか種類が存在しています。このバイナリの種類の事を命令セットアーキテクチャ(Instruction Set Architecture)、ISAと呼びます。基本的に、CPUはISAが異なるバイナリを実行できません。例えばMacのソフトウェアはMacのCPU以外では動きませんし、PCゲームのファイルをスマホに突っ込んでも動きませんね、動かそうとするな。
具体的なISAとしては、x86_64, AArch64, RISC-Vなどが存在しています。
本記事では筆者が定義した独自のISA、Z16のCPUを作ります。Z16のCPUを作る前に一度、本項でZ16のアセンブリに親しみを持っておきましょう。
Z16の概要
Z16は筆者が独自に定義したISAであり、16-bitの固定長命令セットです。16個の16-bitレジスタと16個の命令を持ちます。酒に酔いながら設計しました。
RISC-Vみたいなイケてるロゴを持ってるISAに憧れがあるのでZ16のロゴを以下に置いておきます。ライセンスフリーです。
![]()
Z16のレジスタ
Z16は16bitのレジスタを16個持っています。その内訳は以下の通り、アドレス0のレジスタZRは常に値が0な特殊なレジスタ、レジスタB1~B3は後述しますが分岐命令の対象にすることが可能なレジスタです。残りのレジスタG0~G11は自由に使えるレジスタとなっています。
| アドレス | 名前 | 説明 |
|---|---|---|
0x0 |
ZR |
常に値が0のレジスタ |
0x1 |
B1 |
分岐命令用レジスタ |
0x2 |
B2 |
分岐命令用レジスタ |
0x3 |
B3 |
分岐命令用レジスタ |
0x4 |
G0 |
汎用レジスタ |
0x5 |
G1 |
汎用レジスタ |
0x6 |
G2 |
汎用レジスタ |
0x7 |
G3 |
汎用レジスタ |
0x8 |
G4 |
汎用レジスタ |
0x9 |
G5 |
汎用レジスタ |
0xA |
G6 |
汎用レジスタ |
0xB |
G7 |
汎用レジスタ |
0xC |
G8 |
汎用レジスタ |
0xD |
G9 |
汎用レジスタ |
0xE |
G10 |
汎用レジスタ |
0xF |
G11 |
汎用レジスタ |
レジスタ関連の用語で、値が書き込まれるレジスタをディスティネーションレジスタ、値が読み出されるレジスタをソースレジスタと呼びます。覚えておきましょう。
Z16の命令
次はZ16の命令を見ていきましょう。
演算命令
演算命令のビットフィールドの形式は以下の通り。4bit区切りになっており、下位4bitから順にオペコード、ディスティネーションレジスタ、ソースレジスタ1、ソースレジスタ2となっている。
| instr | [15:12] |
[11:8] |
[7:4] |
[3:0] |
|---|---|---|---|---|
| 演算命令 | rs2[3:0] |
rs1[3:0] |
rd[3:0] |
opcode[3:0] |
ADD
加算命令。レジスタ同士の足し算を行う命令であり、ADD RS2 RS1 RDと記述し、RS2とRS1の値を加算してRDに格納する。オペコードは4'h0。例としてADD G3 G2 G1は16'h7650となる。また、RS2にゼロレジスタZRを指定することで、RS1からRDに値を移動させるだけの命令として使うことが可能です。
$$ \text{RS2} + \text{RS1} \rightarrow \text{RD} $$
実際にZ16のエミュレータでADD命令を使ってみましょう。以下のページにアクセスし、エミュレータにアクセスします。
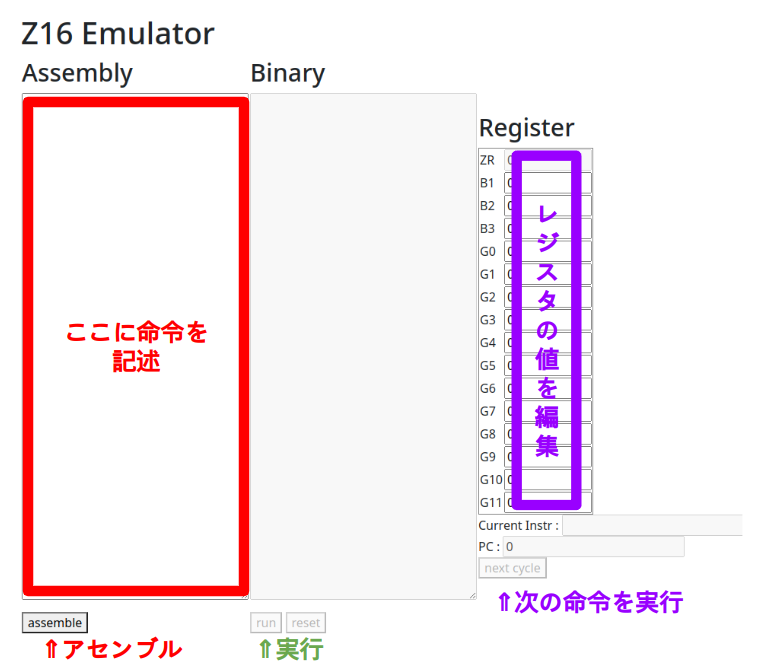
エミュレータの赤で囲われた部分にADD G3 G2 G1と入力し、またレジスタの表のG3とG2に数字を入力します。そしてassembleボタンを押して命令をバイナリに変換し、runボタンを押して命令を実行します。
するとG1の値がG2とG3の加算結果が格納されます。
SUB
減算命令。レジスタ同士の引き算を行う命令であり、SUB RS2 RS1 RDと記述し、RS2からRS1の値を減算してRDに格納する。オペコードは4'h1。例としてSUB G3 G2 G1は16'h7651となる。
$$ \text{RS2} - \text{RS1} \rightarrow \text{RD} $$
MUL
乗算命令。レジスタ同士の掛け算を行う命令であり、MUL RS2 RS1 RDと記述し、RS2とRS1の値を乗算してRDに格納する。オペコードは4'h2。例としてMUL G3 G2 G1は16'h7652となる。
$$ \text{RS2}\times \text{RS1} \rightarrow \text{RD} $$
DIV
除算命令。レジスタ同士の割り算を行う命令であり、DIV RS2 RS1 RDと記述し、RS2をRS1で割った商をRDに格納する。オペコードは4'h3。例としてDIV G3 G2 G1は16'h7653となる。
$$ \text{RS2} \div \text{RS1} \rightarrow \text{RD} $$
OR
OR命令。レジスタ同士のOR演算を行う命令であり、OR RS2 RS1 RDと記述し、RS2とRS1の値のORをRDに格納する。オペコードは4'h4。例としてOR G3 G2 G1は16'h7654となる。
$$ \text{RS2} \parallel \text{RS1} \rightarrow \text{RD} $$
AND
AND命令。レジスタ同士のAND演算を行う命令であり、AND RS2 RS1 RDと記述し、RS2とRS1の値のANDをRDに格納する。オペコードは4'h5。例としてAND G3 G2 G1は16'h7655となる。
$$ \text{RS2} \& \text{RS1} \rightarrow \text{RD} $$
XOR
XOR命令。レジスタ同士のXOR演算を行う命令であり、XOR RS2 RS1 RDと記述し、RS2とRS1の値のXORをRDに格納する。オペコードは4'h6。例としてXOR G3 G2 G1は16'h7656となる。
$$ \text{RS2} \oplus \text{RS1} \rightarrow \text{RD} $$
SLL
論理左シフト命令。レジスタの値の左シフトを行う命令であり、SLL RS2 RS1 RDと記述し、RS1の値をRS2の値だけ論理左シフトしてRDに格納する。オペコードは4'h7。例としてSLL G3 G2 G1は16'h7657となる。
$$ \text{RS1} << \text{RS2} \rightarrow \text{RD} $$
SRL
論理右シフト命令。レジスタの値の右シフトを行う命令であり、SRL RS2 RS1 RDと記述し、RS1の値をRS2の値だけ論理右シフトしてRDに格納する。オペコードは4'h8。例としてSRL G3 G2 G1は16'h7658となる。
演算命令まとめ
以下の計算を行いたい場合、アセンブリとそのバイナリは以下の通りになります。
$$ f(x, y) = x\times y + x - y $$
xの値をG0、yの値をG1、結果をG7に格納する事にします。
アセンブリ
MUL G0 G1 G2
SUB G0 G1 G3
ADD G2 G3 G7
バイナリ
16'h4562
16'h4571
16'h67B0
エミュレータで実際に上記のアセンブリを動かしてみましょう。初期値はG0とG1に入力してください。
演算命令の一覧表
| instr | [15:12] |
[11:8] |
[7:4] |
[3:0] |
|---|---|---|---|---|
| 演算命令 | rs2[3:0] |
rs1[3:0] |
rd[3:0] |
opcode[3:0] |
| opcode[3:0] | name | operation | assembly | binary |
|---|---|---|---|---|
4'h0 |
ADD | rs2 + rs1 ➜ rd |
ADD G3 G2 G1 |
16'h7650 |
4'h1 |
SUB | rs2 - rs1 ➜ rd |
SUB G3 G2 G1 |
16'h7651 |
4'h2 |
MUL | rs2 * rs1 ➜ rd |
MUL G3 G2 G1 |
16'h7652 |
4'h3 |
DIV | rs2 / rs1 ➜ rd |
DIV G3 G2 G1 |
16'h7653 |
4'h4 |
OR | rs2 | rs1 ➜ rd |
OR G3 G2 G1 |
16'h7654 |
4'h5 |
AND | rs2 & rs1 ➜ rd |
AND G3 G2 G1 |
16'h7655 |
4'h6 |
XOR | rs2 ^ rs1 ➜ rd |
XOR G3 G2 G1 |
16'h7656 |
4'h7 |
SLL | rs1 << rs2 ➜ rd |
SLL G3 G2 G1 |
16'h7657 |
4'h8 |
SRL | rs1 >> rs2 ➜ rd |
SRL G3 G2 G1 |
16'h7658 |
即値命令
先で挙げた演算命令だけでは、G0に100を足す、G7から1を引くなどの操作を行うことが出来ないため、命令に値を直接埋め込みたい需要が存在します。そのような、命令に直接埋め込まれている値を即値(immediate)と呼び、即値を含む命令を即値命令と呼びます。
即値命令のビットフィールドの形式は以下の通り、LSBから下位4bitがオペコード、そこから4bitがディスティネーションレジスタ、上位8bitが即値となっています。
| instr | [15:8] |
[7:4] |
[3:0] |
|---|---|---|---|
| 即値命令 | imm[7:0] |
rd[3:0] |
opcode[3:0] |
ADDI
即値加算命令。即値とレジスタで足し算を行う命令であり、ADDI IMM RDと記述し、RDにIMMを加算してRDに格納します。IMMが取れる値の範囲は符号付き8bitなので-128~127。オペコードは4'h9。例としてADDI 100 G0は16'h6449、ADDI -1 G2は16'hFF69となります。
$$ \text{IMM} + \text{RD} \rightarrow \text{RD} $$
実際に即値命令を動かしてみましょう。エミュレータにアクセスし、ADDI 57 G0と入力して実行してみてください。
するとG0に57が格納されます。
即値命令まとめ
以下の計算を行いたい場合、アセンブリとそのバイナリは以下の通りになります。
$$ f(x, y) = 3\times x + 100 + y $$
xの値をG0、yの値をG1、結果をG7に格納する事にします。
アセンブリ
ADDI 3 G4
MUL G4 G0 G2
ADDI 100 G1
ADD G2 G1 G7
バイナリ
16'h0389
16'h8462
16'h6459
16'h65B0
| instr | [15:8] |
[7:4] |
[3:0] |
|---|---|---|---|
| 即値命令 | imm[7:0] |
rd[3:0] |
opcode[3:0] |
| opcode[3:0] | name | operation | assembly | binary |
|---|---|---|---|---|
4'h9 |
ADDI | imm + rd ➜ rd |
ADDI 100 G0 |
16'h6449 |
メモリ命令
Z16ではレジスタは16個あると先に説明しましたが、このままではCPUはデータを16個しか持つ事が出来ません。これではあまり実用的なCPUとは言えません。そこでメモリという記憶装置を作り、扱えるデータの量を増やします。
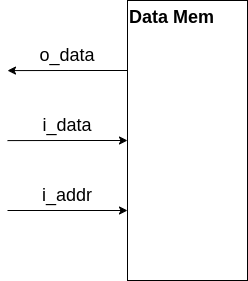
CPUがメモリを扱えるようにするため、メモリからデータを読み書きする専用の命令を定義します。
LOAD
Loadはメモリからデータを取り出す操作であり、Z16ではLOADというLoadを行う命令を一つ持っています。
LOAD命令のビットフィールドの形式は以下の通り、LSBから下位4bitはオペコード、そこから4bitずつにディスティネーションレジスタ、ソースレジスタ1、即値となっている。
| instr | [15:12] |
[11:8] |
[7:4] |
[3:0] |
|---|---|---|---|---|
| LOAD命令 | imm[3:0] |
rs1[3:0] |
rd[3:0] |
opcode[3:0] |
LOAD命令。LOAD IMM RS1 RDと記述し、IMMとRS1の値の和をメモリアドレスとし、メモリのそのアドレスにあるデータをRDに格納する。IMMが取れる値の範囲は符号付き4bitであるため-8~7。オペコードは4'hAであるため、仮にLOAD 0 G0 G1は16'h045Aとなる。
$$ \text{Memory}[\text{IMM} + \text{RS1}] \rightarrow \text{RD} $$
STORE
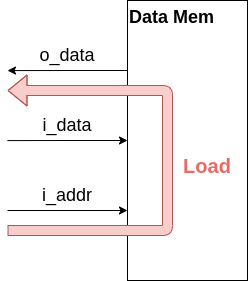
Storeはメモリにデータを書き込む操作であり、Z16ではSTOREというStoreを行う命令を一つ持っている。
STORE命令のビットフィールドは以下の通り、LSBから下位4bitがオペコード、そこから4bitずつに即値、ソースレジスタ1、ソースレジスタ2となっている。
| instr | [15:12] |
[11:8] |
[7:4] |
[3:0] |
|---|---|---|---|---|
| STORE命令 | rs2[3:0] |
rs1[3:0] |
imm[3:0] |
opcode[3:0] |
STORE命令。STORE RS2 RS1 IMMと記述し、IMMとRS1の値の和をメモリアドレスとし、RS2の値をメモリのそのアドレスに格納する。IMMが取れる値の範囲は符号付き4bitであるため-8~7。オペコードは4'hBであるため、仮にSTORE G1 G0 0は16'h540Bとなる。
$$ \text{RS2} \rightarrow \text{Memory}[\text{RS1} + \text{IMM}] $$
メモリ命令まとめ
エミュレータにアクセスし、実際にメモリ命令を動かしてみましょう。
以下の命令をエミュレータにコピペし、またG0に適当な数字を入れます。
STORE G0 ZR 0
LOAD 0 ZR G1
その後実行すると、G0のデータがメモリを介してG1に入力されます。
| instr | [15:12] |
[11:8] |
[7:4] |
[3:0] |
|---|---|---|---|---|
| LOAD命令 | imm[3:0] |
rs1[3:0] |
rd[3:0] |
opcode[3:0] |
| STORE命令 | rs2[3:0] |
rs1[3:0] |
imm[3:0] |
opcode[3:0] |
| opcode[3:0] | name | operation | assembly | binary |
|---|---|---|---|---|
4'hA |
LOAD | [imm + rs1] ➜ rd |
LOAD 4 G5 G6 |
16'h49AA |
4'hB |
STORE | rs2 ➜ [rs1 + imm] |
STORE G5 G6 2 |
16'h9A2B |
ジャンプ命令
ジャンプ命令とは文字通りジャンプする命令であり、プログラムの流れを強制的に変更します。
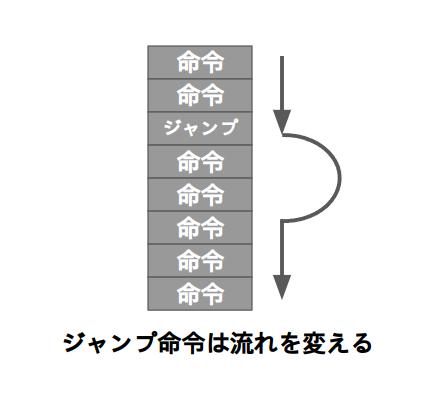
ジャンプ命令のビットフィールドは以下の通り、LSBから下位4bitがオペコード、そこから4bitずつにディスティネーションレジスタ、ソースレジスタ1、即値となっている。
| instr | [15:12] |
[11:8] |
[7:4] |
[3:0] |
|---|---|---|---|---|
| ジャンプ命令 | imm[3:0] |
rs1[3:0] |
rd[3:0] |
opcode[3:0] |
JAL
JALはJump Absolute and Link の略であり、JAL IMM RS1 RDと記述する。動作としてはIMMとRS1の値の和にジャンプすると同時に、JALの次の命令のアドレスをRDに格納する。
即値のフィールドは符号付き4bitであり、-8~7の値を取る。
$$ \begin{align} \text{PC} + 2 &\rightarrow \text{RD} \\ \text{IMM} + \text{RS1} &\rightarrow \text{PC} \end{align} $$
実際にJAL命令を使ってみましょう。エミュレータにアクセスし、以下の命令列を実行します。
ADD ZR ZR ZR
JAL 6 ZR G0
XOR ZR ZR ZR
SUB ZR ZR ZR
next cycleボタンを押していくと、JAL命令が実行された際に、実行中の命令のアドレス(PC)が6になり、XOR命令を飛ばしてSUB命令が実行されます。またJAL命令の次の命令のアドレスがG0に格納されます。
JRL
JRLはJump Relative and Linkの略であり、JRL IMM RS1 RDと記述する。動作としてはIMMとRS1の値とJRLが存在するアドレスの和にジャンプすると同時に、JRLの次の命令のアドレスをRDに格納する。
即値のフィールドは符号付き4bitであり、-8~7の値を取る。
$$ \begin{align} \text{PC} + 2 &\rightarrow \text{RD} \\ \text{IMM} + \text{RS1} + \text{PC} &\rightarrow \text{PC} \end{align} $$
特殊な使い方として、JRL 0 ZR ZRとすることでプログラムを停止させる事が可能である。
実際にJAL命令を使ってみましょう。エミュレータにアクセスし、以下の命令列を実行します。
ADD ZR ZR ZR
SUB ZR ZR ZR
JRL -4 ZR G0
AND ZR ZR ZR
XOR ZR ZR ZR
next cycleボタンをクリックしていき、JRL命令が実行されると実行中のアドレスから4が引かれ、2つ前の命令にジャンプします。またJRL命令の次の命令のアドレスがG0に格納されます。
またプログラム停止させる命令であるJRL 0 ZR ZRも試してみましょう。以下のプログラムをエミュレータで実行すると、JRLが実行された後は実行中のアドレス(PC)がnext cycleボタンを押しても動かなくなります。
ADD ZR ZR ZR
SUB ZR ZR ZR
AND ZR ZR ZR
XOR ZR ZR ZR
JRL 0 ZR ZR
ジャンプ命令まとめ
JALのような、指定したアドレスに飛ぶジャンプの事を絶対ジャンプと呼び、JRLのような自身のアドレスを基準に飛ぶジャンプのことを相対ジャンプと呼ぶ。
以下の命令列では、アドレス4の位置にJRLが存在しています。この命令列が実行されると、JRLでアドレスAの命令にジャンプしAND命令が実行されます。またレジスタG6には6が格納されます。
0: ADD G0 G1 G2
2: SUB G0 G1 G2
4: JRL 6 ZR G6
6: MUL G0 G1 G2
8: DIV G0 G1 G2
A: AND G0 G1 G2
C: XOR G0 G1 G2
E: ADD G0 G1 G2
ジャンプ命令一覧表
| instr | [15:12] |
[11:8] |
[7:4] |
[3:0] |
|---|---|---|---|---|
| ジャンプ命令 | imm[3:0] |
rs1[3:0] |
rd[3:0] |
opcode[3:0] |
| opcode[3:0] | name | operation | assembly | binary |
|---|---|---|---|---|
4'hC |
JAL | pc + 2 ➜ rd imm + rs1 ➜ pc |
JAL 4 G7 G8 |
16'h4BCC |
4'hD |
JRL | pc + 2 ➜ rd imm + rs1 + pc ➜ pc |
JRL 4 G7 G8 |
16'h4BCD |
分岐命令
分岐命令とは文字通り分岐を行う命令であり、強制的にプログラムの流れを変えるジャンプ命令とは異なり、条件に合致した場合にプログラムの流れを変える。
分岐命令のビットフィールドは以下の通りであり、LSBから下位4bitがオペコード、そこから2bitがソースレジスタ1、続いて2bitがソースレジスタ2、MSBから8bitが即値となっている。
| instr | [15:8] |
[7:6] |
[5:4] |
[3:0] |
|---|---|---|---|---|
| 分岐命令 | imm[7:0] |
rs2[1:0] |
rs1[1:0] |
opcode[3:0] |
レジスタを指定するフィールドの幅がそれぞれ2bitであるため、0~3番目のレジスタZR, B0, B1, B2のみをソースレジスタに指定できる。
BEQ
BEQとは、Branch Equalの略であり、BEQ RS2 RS1 IMMと記述する。動作としてはRS1とRS2の値が等しい場合に自身のアドレスに即値を加えたアドレスにジャンプする。オペコードは4'hEであるため、仮にBEQ B2 B1 100は16'h649Eとなる。
即値のフィールドは符号付き8bitであり、-128~127の値を取る。
$$ \begin{align} \text{if}\ \text{RS2}\ &== \text{RS1} \\ \text{then}\ \text{imm} &+ \text{PC} \rightarrow \text{PC} \end{align} $$
実際にBEQ命令を使ってみましょう。エミュレータにアクセスし、以下の命令列を実行します。
BEQ B1 B2 4
ADD G1 G2 G3
SUB G1 G2 G3
JRL 0 ZR ZR
next cycleボタンを押していくと、B1とB2の値が異なる場合はBEQから順に通常通りに実行され、B1とB2の値が同じ場合はADD命令が飛ばれます。B1とB2の値を変えて試してみてください。
BLT
BLTとは、Branch Less Thanの略であり、BLT RS2 RS1 IMMと記述する。動作としてはRS2の値がRS1の値より大きい場合に自身のアドレスに即値を加えたアドレスにジャンプする。オペコードは4'hFであるため、仮にBLT B2 ZR 100は16'h644Fとなる。
即値のフィールドは符号付き8bitであり、-128~127の値を取る。
$$ \begin{align} \text{if}\ \text{RS2}\ &> \text{RS1} \\ \text{then}\ \text{imm} &+ \text{PC} \rightarrow \text{PC} \end{align} $$
実際にBEQ命令を使ってみましょう。エミュレータにアクセスし、以下の命令列を実行します。
ADDI -4 B1
ADDI 10 B2
BLT B2 B1 4
ADD ZR ZR ZR
SUB G7 G7 G7
next cycleボタンを押していくとBLT命令で10 > -4が評価され、真であるため分岐が発生し、実行している命令アドレスに4が加算されADD命令が飛ばされSUB命令が実行されます。
分岐命令まとめ
分岐命令を用いる事で、かなり柔軟にプログラムを書くことが可能となる。以下の例は1~10の総和を求め、アドレス8で停止するプログラムである。
アセンブリ
0: ADDI 10 B1
2: ADD B1 B2 B2
4: ADDI -1 B1
6: BLT B1 ZR -4
8: JRL 0 ZR G11
バイナリ
16'h0A19
16'h1220
16'hFF19
16'hFC4F
16'h00FD
このアセンブリをエミュレータで実際に動かしてみましょう。エミュレータにアクセスし、上記のアセンブリをコピペして実行してみてください。
PCが停止するまでnext cycleボタンを押していくと、B2に1~10の総和が格納されます。
分岐命令一覧表
| instr | [15:8] |
[7:6] |
[5:4] |
[3:0] |
|---|---|---|---|---|
| 分岐命令 | imm[7:0] |
rs2[1:0] |
rs1[1:0] |
opcode[3:0] |
| opcode[3:0] | name | operation | assembly | binary |
|---|---|---|---|---|
4'hE |
Branch equal | if rs2 == rs1 then imm + pc ➜ pc |
BEQ B1 B2 -4 |
16'hFC5E |
4'hF |
Branch Less than | if rs2 > rs1 then imm + pc ➜ pc |
BLT B1 B2 -12 |
16'hF45F |
Z16のエミュレータ
アセンブラ及びエミュレータとしてご利用ください。
ディジタルビルディングブロック
座学は終わりです。実際に手を動かしていきましょう。
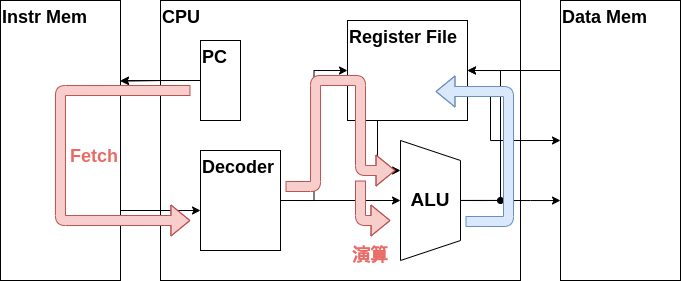
これはCPUの大まかな内部構造です。ご覧の通りCPUは多くの部品で構成されていますが、各部品はそこまで複雑ではありません。本章ではCPUの各部品について説明し、実際に実装していきます。
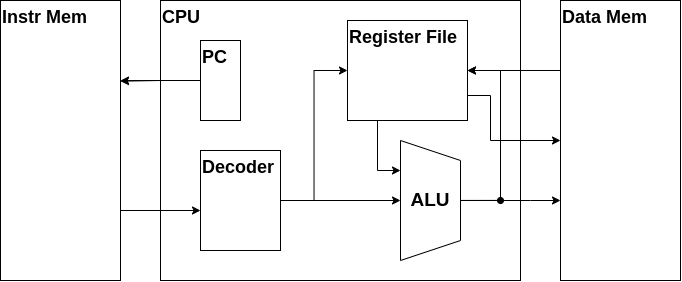
Register File
Register File、これはレジスタファイルと呼び、CPUが少量のデータを保持するのに使います。

動作としてはアドレスを入力するとデータを出力する読み出しと、

アドレスとデータを入力するとレジスタファイルに書き込まれる書き込みを行います。

仕様策定
レジスタファイルの働きを理解したところで、我々が実装するレジスタファイルの仕様を決めましょう。
Z16は16bitのレジスタを16個持っていると説明しました。よって16bitのレジスタが16個必要です。そのまんまですね。
- 16bitのレジスタ x 16
またZ16の演算命令を思い出してください。Z16の演算命令はADD RS2 RS1 RDのように、レジスタファイルから2つのデータを読み出し、演算結果である1つのデータをレジスタファイルへ書き込みます。つまり読み出すためのポートは2つ必要で、書き込むためのポートは1つ必要です。
- 読み出しポート x 2
- 書き込みポート x 1
そしてZ16には特殊なレジスタとして、ZRが定義されていました。これは常に値が0のレジスタでしたね。読み出しても書き込んでも常に値が0のレジスタは、値を読み出すために入力されたアドレスが0の場合に0を出力する機構を作れば実装が可能です。このZRの事を便宜上ゼロレジスタと呼びます。
- ゼロレジスタ
レジスタファイルの仕様はこんなところですかね。仕様をまとめると以下になります。今後もモジュールを作る時は仕様をまず決めましょう。
- 16bitのレジスタ x 16
- 読み出しポート x 2
- 書き込みポート x 1
- ゼロレジスタ
実装
では実装に移ります。Z16RegisterFile.vという名前のファイルを作成して、以下の記述を書き写してください。コピペではダメです。最初はインターフェイスから作成しましょう。
読み出しポートを2つ作ります。i_rs1_addrとo_rs1_data、i_rs2_addrとo_rs2_dataは両方とも4bitのアドレス入力を受け、16bitのデータを出力する読み出しポートです。
次に書き込みポートを1つ作ります。i_rd_addrは書き込み先アドレス入力、i_rd_wenが書き込みの有効化、i_rd_dataが書き込みデータとなっています。Z16にはレジスタに値を書き込まない命令もありますので、i_rd_wenで書き込むか否かを制御出来るようにしています。
module Z16RegisterFile(
input wire i_clk, // クロック
input wire [3:0] i_rs1_addr, // RS1アドレス
output wire [15:0] o_rs1_data, // RS1読み出しデータ
input wire [3:0] i_rs2_addr, // RS2アドレス
output wire [15:0] o_rs2_data, // RS2読み出しデータ
input wire [3:0] i_rd_addr, // RDアドレス
input wire i_rd_wen, // RD書き込み有効化
input wire [15:0] i_rd_data // RD書き込みデータ
);
// ここに回路を記述
endmodule
次に16bitのレジスタを16個作成しましょう。regの二次元配列を使えば一撃です。
// レジスタファイル本体
reg [15:0] mem[15:0];
次にレジスタの読み出し機構を作ります。三項演算子を使っており一見トリッキーに見えますがその実シンプルです。i_rs1_addr == 4'h0で入力されたアドレスが0の場合は16'h0000を出力し、それ以外の場合はmem[i_rs1_addr]でレジスタファイルから値を取り出し、o_rs1_dataへデータを出力しています。RS2の場合も同様です。
ここのアドレスが0の場合に0を出力する機構が、ゼロレジスタの実装となっています。
// Read
// アドレスが0なら0を出力
assign o_rs1_data = (i_rs1_addr == 4'h0) ? 16'h0000 : mem[i_rs1_addr];
assign o_rs2_data = (i_rs2_addr == 4'h0) ? 16'h0000 : mem[i_rs2_addr];
最語にレジスタへの書き込み機構を作ります。こちらは簡単です。i_rd_wenが1になり、書き込みが有効化された時にのみmem[i_rd_addr]で指定したレジスタに対してi_rd_dataの値を書き込んでいます。それ以外の場合は値が更新されないようにしています。
// Write
always @(posedge i_clk) begin
if(i_rd_wen) begin
mem[i_rd_addr] <= i_rd_data;
end else begin
mem[i_rd_addr] <= mem[i_rd_addr];
end
end
以上の記述をまとめたものが以下になります。書き写した内容と見比べるのに使ってください。
module Z16RegisterFile(
input wire i_clk, // クロック
input wire [3:0] i_rs1_addr, // RS1アドレス
output wire [15:0] o_rs1_data, // RS1読み出しデータ
input wire [3:0] i_rs2_addr, // RS2アドレス
output wire [15:0] o_rs2_data, // RS2読み出しデータ
input wire [3:0] i_rd_addr, // RDアドレス
input wire i_rd_wen, // RD書き込み有効化
input wire [15:0] i_rd_data // RD書き込みデータ
);
// レジスタファイル本体
reg [15:0] mem[15:0];
// Read
// アドレスが0なら0を出力
assign o_rs1_data = (i_rs1_addr == 4'h0) ? 16'h0000 : mem[i_rs1_addr];
assign o_rs2_data = (i_rs2_addr == 4'h0) ? 16'h0000 : mem[i_rs2_addr];
// Write
always @(posedge i_clk) begin
if(i_rd_wen) begin
mem[i_rd_addr] <= i_rd_data;
end else begin
mem[i_rd_addr] <= mem[i_rd_addr];
end
end
endmodule
動作の確認
これでレジスタファイルが完成しました。テストベンチで動作を確認しましょう。以下のテストベンチでは、0xA番目のレジスタに16'h5555を書き込んだ後、RS1とRS2両方のポートから読み出しています。
module Z16RegisterFile_tb;
reg i_clk = 1'b0;
reg [3:0] i_rs1_addr;
reg [3:0] i_rs2_addr;
reg [3:0] i_rd_addr;
reg i_rd_wen;
reg [15:0] i_rd_data;
wire [15:0] o_rs1_data;
wire [15:0] o_rs2_data;
always #1 begin
i_clk <= ~i_clk;
end
initial begin
$dumpfile("wave.vcd");
$dumpvars(0, Z16RegisterFile_tb);
end
Z16RegisterFile Regfile(
.i_clk (i_clk ),
.i_rs1_addr (i_rs1_addr ),
.i_rs2_addr (i_rs2_addr ),
.i_rd_addr (i_rd_addr ),
.i_rd_wen (i_rd_wen ),
.i_rd_data (i_rd_data ),
.o_rs1_data (o_rs1_data ),
.o_rs2_data (o_rs2_data )
);
initial begin
i_rd_wen = 1'b0;
i_rs1_addr = 4'h0;
i_rs2_addr = 4'h0;
#2
// 値を書き込み
i_rd_wen = 1'b1;
i_rd_addr = 4'hA;
i_rd_data = 16'h5555;
#2
i_rd_wen = 1'b0;
#2
// RS1から値を読み出し
i_rs1_addr = 4'hA;
#2
// RS2から値を読み出し
i_rs2_addr = 4'hA;
#2
$finish;
end
endmodule
以下のコマンドで動作を確認できます。
iverilog Z16RegisterFile_tb.v Z16RegisterFile.v
vvp a.out
gtkwave wave.vcd
Data Mem
Data Mem、これはデータメモリと呼び。CPUがレジスタファイルに収まらない大量のデータを保存するのに使います。CPUはデータメモリ対してデータの書き込みと読み出しを行います。
メモリに対してのデータ書き込みと読み出しにはそれぞれ名前があり、メモリへのデータ書き込みをストア(Store)、
メモリからのデータ読み出しをロード(Load)と呼びます。Store命令、Load命令とよく使われる単語ですので覚えておきましょう。
仕様策定
データメモリの役割を理解したところで、我々が作成するデータメモリの仕様を決めましょう。
まずはデータメモリのサイズを決めます。Z16ではメモリアドレスとして16bitの値が使えるので、最大65536(2^16) x 16bitのサイズを持つデータメモリを作成することが出来ます。ですが、本記事では非常に効率の悪いデータメモリの実装を行うので、そこまで大きなメモリを作ることは出来ません。そこで本記事では1024 x 16bitのデータメモリを作ることにします。
- 1024 x 16bit
次にインターフェイスの仕様を決めましょう。Z16においてLOAD命令はデータメモリから1つのデータを取り出し、STORE目入れはデータメモリに1つのデータを書き込みます。よってZ16のメモリは1つの読み出しポートと1つの書き込みのポートがあれば十分です。またLOAD命令とSTORE命令が同時に実行されることはありませんので、アドレス入力はLOADとSTOREで共通にします。
- 読み出しポート x 1
- 書き込みポート x 1
- アドレス入力は共通
ここまでで決めたデータメモリの仕様を以下にまとめます。
- 1024 x 16bit
- 読み出しポート x 1
- 書き込みポート x 1
- アドレス入力は共通
データメモリを実装するのに必要な仕様はこんなもんでしょう。実装に移ります。
実装
ではデータメモリの実装をしていきます。Z16DataMemory.vという名前のファイルを作成して以下の記述を書き写してください。最初はインターフェイスから作成しましょう。
まずは読み出しと書き込み先を指定するアドレス入力であるi_addrを定義し、続いて書き込み有効化信号のi_wen、書き込みデータのi_data、読み出しデータのo_dataを定義しています。
module Z16DataMemory(
input wire i_clk, // クロック
input wire [15:0] i_addr, // アドレス
input wire i_wen, // 書き込み制御
input wire [15:0] i_data, // 書き込みデータ
output wire [15:0] o_data // 読み出しデータ
);
// ここに回路を記述
endmodule
次に16bit x 1024サイズのメモリを作成しましょう。こちらもレジスタファイルと同じくregの二次元配列を使えば一撃です。
reg [15:0] mem[1023:0];
続いてLOADを行う機構を作成しましょう。i_addrで指定されたメモリアドレスを用いてmem[i_addr[10:1]]でメモリからデータを取り出し、o_dataへデータを出力しています。
// Load
assign o_data = mem[i_addr[10:1]];
最後にSTOREを行う機構を作成しましょう。これは非常に単純です。i_wenでデータ書き込みが有効な場合に、i_addrで指定されたメモリアドレスを用いてmem[i_addr[10:1]]でメモリを指定し、i_dataのデータを入力しています。
always @(posedge i_clk) begin
// Store
if(i_wen) begin
mem[i_addr[10:1]] <= i_data;
end
end
これでデータメモリは完成です。以上の記述をまとめたものが以下になります。書き写した内容と見比べるのに使ってください。
module Z16DataMemory(
input wire i_clk, // クロック
input wire [15:0] i_addr, // アドレス
input wire i_wen, // 書き込み制御
input wire [15:0] i_data, // 書き込みデータ
output wire [15:0] o_data // 読み出しデータ
);
reg [15:0] mem[1023:0];
// Load
assign o_data = mem[i_addr[10:1]];
always @(posedge i_clk) begin
// Store
if(i_wen) begin
mem[i_addr[10:1]] <= i_data;
end
end
endmodule
動作の確認
データメモリが完成しましたら、テストベンチで動作を確認しましょう。以下のテストベンチでは、0x100番目のアドレスに16'h5555をストアした後、ロードしています。
module Z16DataMemory_tb;
reg i_clk = 1'b0;
reg [15:0] i_addr;
reg i_wen;
reg [15:0] i_data;
wire [15:0] o_data;
always #1 begin
i_clk <= ~i_clk;
end
initial begin
$dumpfile("wave.vcd");
$dumpvars(0, Z16DataMemory_tb);
end
Z16DataMemory DataMem(
.i_clk (i_clk ),
.i_addr (i_addr ),
.i_wen (i_wen ),
.i_data (i_data ),
.o_data (o_data )
);
initial begin
i_wen = 1'b0;
#2
// ストア
i_wen = 1'b1;
i_addr = 16'h0100;
i_data = 16'h5555;
#2
i_wen = 1'b0;
i_addr = 16'h0000;
#2
// ロード
i_addr = 16'h0100;
#2
$finish;
end
endmodule
以下のコマンドで動作を確認できます。
iverilog Z16DataMemory_tb.v Z16DataMemory.v
vvp a.out
gtkwave wave.vcd
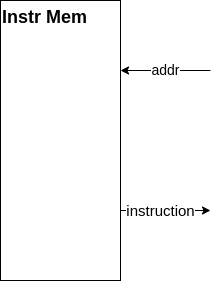
Instr Mem
Instr Mem、これは命令メモリ(Instruction Memory)と呼び、データメモリに似ていますが中には命令が入っています。命令メモリ内の各命令にはアドレスが振られており、命令メモリにアドレスを入力すると命令が出力されます。
仕様策定
命令メモリの役割を理解したところで、我々が作成する命令メモリの仕様を決めましょう。
命令メモリは読み出ししか行えないメモリですので、読み出しポートが1つあれば十分です。
- 読み出しポート x 1
また命令メモリのサイズですが、これは今の所は格納する命令列と同じサイズにしておきます。つまりサイズは命令長 x 16bitです。
- 命令長 x 16bit
決定した命令メモリの仕様を以下にまとめます。
- 読み出しポート x 1
- 命令長 x 16bit
短いですね。実装に移ります。
実装
では命令メモリの実装をしていきます。Z16InstrMemory.vという名前のファイルを作成して以下の記述を書き写してください。最初はインターフェイスから作成しましょう。
命令メモリはアドレスを受け取って命令を出力する回路ですので、定義すべきインターフェイスはアドレス入力であるi_addrと命令出力のo_instrだけです。
module Z16InstrMemory(
input wire [15:0] i_addr, // アドレス入力
output wire [15:0] o_instr // 命令出力
);
// ここに回路を記述
endmodule
次に16bit x 命令長サイズの命令メモリを作成しましょう。こちらはwireの二次元配列を使います。また格納する命令長は5とします。
wire [15:0] mem[4:0];
続いて命令を読み出す機構を作成しましょう。i_addrで指定されたメモリアドレスを用いてmem[i_addr[15:1]]でメモリからデータを取り出し、o_instrへデータを出力しています。
assign o_instr = mem[i_addr[15:1]];
最後に命令メモリに書き換えが不可能な形で命令を書き込みます。memはwireで定義されていますので、書き込む時はassignです。mem[]でアドレスを指定し、命令を入力しています。ここでは初期値として1~10の総和を求めるプログラムを格納してあります。
assign mem[0] = 16'h0A19;
assign mem[1] = 16'h1220;
assign mem[2] = 16'hFF19;
assign mem[3] = 16'hFC4F;
assign mem[4] = 16'h00FD;
これで命令メモリは完成です。以上の記述をまとめたものが以下になります。書き写した内容と見比べるのに使ってください。
module Z16InstrMemory(
input wire [15:0] i_addr, // アドレス入力
output wire [15:0] o_instr // 命令出力
);
wire [15:0] mem[4:0];
assign o_instr = mem[i_addr[15:1]];
assign mem[0] = 16'h0A19;
assign mem[1] = 16'h1220;
assign mem[2] = 16'hFF19;
assign mem[3] = 16'hFC4F;
assign mem[4] = 16'h00FD;
endmodule
動作の確認
命令メモリが完成しましたら、テストベンチで動作を確認しましょう。以下のテストベンチでは全ての命令をクロック毎に読み出しています。
module Z16InstrMemory_tb;
reg [15:0] i_addr;
wire [15:0] o_instr;
initial begin
$dumpfile("wave.vcd");
$dumpvars(0, Z16InstrMemory_tb);
end
Z16InstrMemory InstrMem(
.i_addr (i_addr ),
.o_instr(o_instr)
);
initial begin
#2
i_addr = 16'h0000;
#2
i_addr = 16'h0002;
#2
i_addr = 16'h0004;
#2
i_addr = 16'h0006;
#2
i_addr = 16'h0008;
#2
$finish;
end
endmodule
以下のコマンドで動作を確認できます。
iverilog Z16InstrMemory_tb.v Z16InstrMemory.v
vvp a.out
gtkwave wave.vcd
ALU
次はALUです。これは算術論理演算ユニット(Arithmetic Logic Unit)の略称で、論理演算(and, or, xor, シフト, etc..)と算術演算(加算, 減算, etc…)を行うモジュールです。CPUにおいて”計算”はこのALUが行っていると考えていただいて構いません。ALUは制御信号と2つのデータを受け取り、1つのデータを出力します。
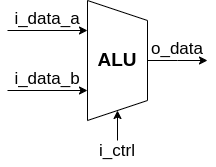
仕様策定
ALUの役割を理解したところで、我々が作成するALUの仕様を決めましょう。
ALUは2つのデータを受け取って演算を行い、演算結果を出力するモジュールですので、データ入力ポートを2つとデータ出力ポートが1つ必要です。
- データ入力ポート x 2
- データ出力ポート x 1
またALUがどの演算を行うのか制御出来るように制御信号入力ポートが1つ必要です。
- 制御信号入力ポート x 1
次に制御信号がどの演算に対応するのか決めましょう。Z16では、演算命令においては多彩な演算が求められますが、それ以外の命令に関しては基本的に加算さえ行えば十分となっています。例えばLOAD命令はMem[IMM + RS1] -> RDという操作を行う命令であり、アドレス計算においてALUによるIMM + RS1の加算が必要です。また即値命令にはADDI命令しかありません。よって演算命令以外では加算を行えば十分です。
そこで、制御信号と演算の対応を演算命令のオペコードと一致させ、演算命令以外のオペコードでは加算を行わせましょう。ややこしく感じるかもしれません。そういう時は実装と演算命令まとめの表を見比べてください。
- 演算と演算命令のオペコードを一致させる、演算命令以外は加算
ここまでで決めたデータメモリの仕様を以下にまとめます。
- データ入力ポート x 2
- データ出力ポート x 1
- 制御信号入力ポート x 1
- 演算と演算命令のオペコードを一致させる、演算命令以外は加算
実装
ではALUの実装をしていきます。Z16ALU.vという名前のファイルを作成して以下の記述を書き写してください。最初はインターフェイスから作成しましょう。
まずはデータ入力ポートを2つ、i_data_aとi_data_bを定義します。続いて制御信号入力のi_ctrl、そしてデータ出力ポートのo_dataを定義します。
module Z16ALU(
input wire [15:0] i_data_a, // データ入力1
input wire [15:0] i_data_b, // データ入力2
input wire [3:0] i_ctrl, // 制御信号入力
output wire [15:0] o_data // データ出力
);
// ここに回路を記述
endmodule
続いて演算を行う機構を作成します。ALUの演算は入力があると即座に結果が出力される、組み合わせ回路で行って欲しいのでassign文を使いますが、i_ctrlによる演算の制御を行いたいので、ここは複雑な記述が出来るfunction文を使います。
よってaluという名前の関数をfunction文で作成します。これはcase文でi_ctrlの値に応じて演算を切り替えるようにしています。例えばi_ctrlの値が5の場合は、オペコードが5の命令は演算命令のAND命令ですのでAND命令を行います。また制御信号が演算命令のオペコードの範囲外の場合は加算を行います。
function [15:0] alu;
input [15:0] i_data_a;
input [15:0] i_data_b;
input [3:0] i_ctrl;
begin
case(i_ctrl)
4'h0 : alu = i_data_b + i_data_a;
4'h1 : alu = i_data_b - i_data_a;
4'h2 : alu = i_data_b * i_data_a;
4'h3 : alu = i_data_b / i_data_a;
4'h4 : alu = i_data_b | i_data_a;
4'h5 : alu = i_data_b & i_data_a;
4'h6 : alu = i_data_b ^ i_data_a;
4'h7 : alu = i_data_a << i_data_a;
4'h8 : alu = i_data_a >> i_data_a;
default: alu = i_data_b + i_data_a;
endcase
end
endfunction
そして先程作成した関数alu()を用いて、計算結果をo_dataに入力します。
assign o_data = alu(i_data_a, i_data_b, i_ctrl);
これでALUは完成です。以上の記述をまとめたものが以下になります。書き写した内容と見比べるのに使ってください。
module Z16ALU(
input wire [15:0] i_data_a,
input wire [15:0] i_data_b,
input wire [3:0] i_ctrl,
output wire [15:0] o_data
);
assign o_data = alu(i_data_a, i_data_b, i_ctrl);
function [15:0] alu;
input [15:0] i_data_a;
input [15:0] i_data_b;
input [3:0] i_ctrl;
begin
case(i_ctrl)
4'h0 : alu = i_data_b + i_data_a;
4'h1 : alu = i_data_b - i_data_a;
4'h2 : alu = i_data_b * i_data_a;
4'h3 : alu = i_data_b / i_data_a;
4'h4 : alu = i_data_b | i_data_a;
4'h5 : alu = i_data_b & i_data_a;
4'h6 : alu = i_data_b ^ i_data_a;
4'h7 : alu = i_data_a << i_data_a;
4'h8 : alu = i_data_a >> i_data_a;
default: alu = i_data_b + i_data_a;
endcase
end
endfunction
endmodule
動作の確認
ALUが完成しましたら、テストベンチで動作を確認しましょう。以下のテストベンチでは、i_data_aに0x4を入力し、またi_data_bに0x8を入力してから加算、減算、乗算、除算、ORを行っています。
module Z16ALU_tb;
reg [15:0] i_data_a;
reg [15:0] i_data_b;
reg [3:0] i_ctrl;
wire [15:0] o_data;
initial begin
$dumpfile("wave.vcd");
$dumpvars(0, Z16ALU_tb);
end
Z16ALU ALU(
.i_data_a (i_data_a ),
.i_data_b (i_data_b ),
.i_ctrl (i_ctrl ),
.o_data (o_data )
);
initial begin
i_data_a = 16'h0004;
i_data_b = 16'h0008;
i_ctrl = 4'h0; // ADD
#2
i_ctrl = 4'h1; // SUB
#2
i_ctrl = 4'h2; // MUL
#2
i_ctrl = 4'h3; // DIV
#2
i_ctrl = 4'h4; // OR
#2
$finish;
end
endmodule
以下のコマンドで動作を確認できます。
iverilog Z16ALU_tb.v Z16ALU.v
vvp a.out
gtkwave wave.vcd
PC
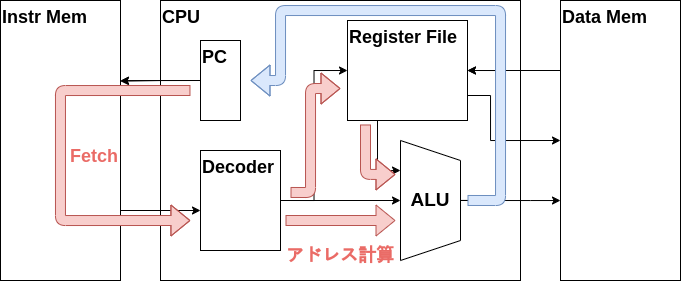
このCPUの中にあるPCはプログラムカウンタ(Program Counter)と呼び、命令メモリにアドレスを供給します。通常、プログラムは上から下に実行されるのでプログラムカウンタが出す値は毎クロック増えていきます。
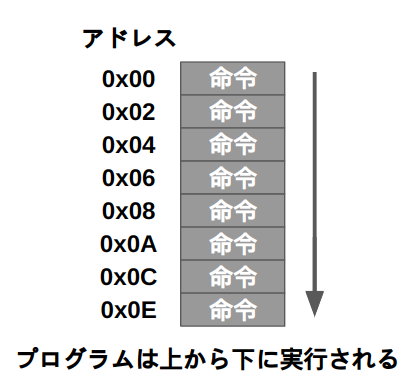
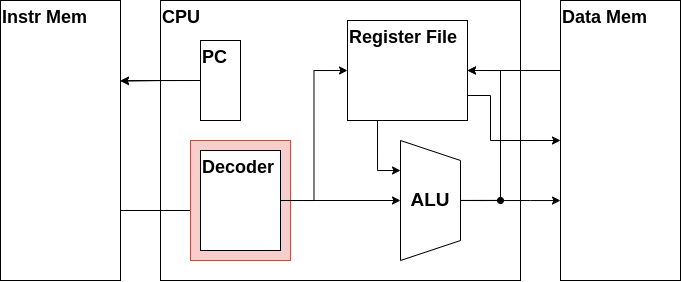
プログラムカウンタ・命令メモリ・CPUの関係をまとめると、プログラムカウンタがアドレスを命令メモリに入力し、命令メモリが命令をCPUへを出力するという流れになります。このデータの流れをフェッチ(Fetch)と呼びます。覚えておきましょう。
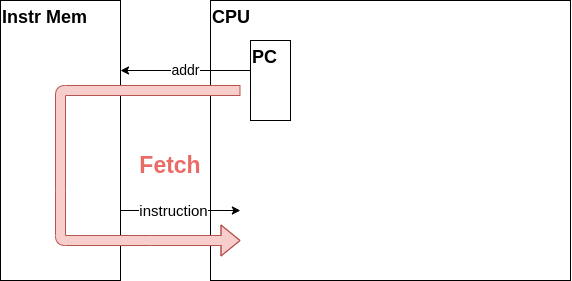
プログラムカウンタは後ほど実装します。
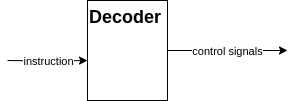
Decoder
最後はDecoderです。これはデコーダと呼び、命令から各種制御信号を生成します。具体的な動作の説明はCPUを実際に作成する際に説明しますので、とりあえず今は命令に応じて各部品を制御するモジュールだと認識しておいてください。
マイクロアーキテクチャ
さて、CPUの部品が一通り実装できましたね。本章では実装した部品を実際に組み立て、CPUとしての動作が出来るようにしていきましょう。
たたき台となるコードを以下に用意しました。以下のコードをZ16CPU.vという名前で保存してください。このたたき台には命令メモリとデータメモリが未接続の状態で置いてあります。
module Z16CPU(
input wire i_clk,
input wire i_rst
);
// 命令メモリ
Z16InstrMem InstrMem(
.i_addr (),
.o_instr ()
);
// データメモリ
Z16DataMem DataMem(
.i_clk (),
.i_addr (),
.i_wen (),
.i_data (),
.o_data ()
);
endmodule
Load命令
最初に実装する命令はLOAD命令です。LOAD命令はメモリからデータを取り出してレジスタに保存する操作でしたね、このLOAD命令の動作を箇条書きにするとこのようになります。
- 命令メモリから命令をフェッチ
- デコーダが命令を解釈
- レジスタからRS1の値を取り出す
- ALUでアドレス計算
- データメモリからデータを取り出す
- レジスタにデータを書き込む
かなり手順が多いですね、実際LOAD命令はZ16の命令の中で最もデータの流れが長い命令となっています。CPUを実装する際はこのLOAD命令のようなデータの流れ、つまりデータパスが最も長い命令を最初に実装した方が楽です。
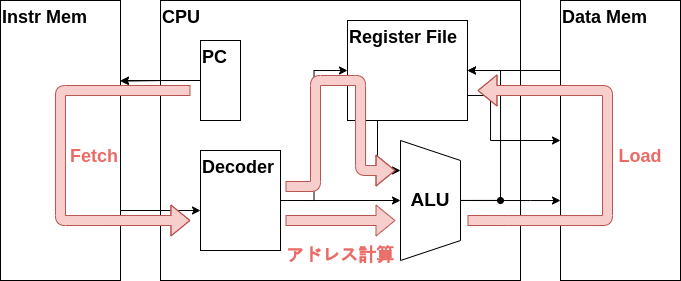
命令フェッチ
ではまずは命令メモリから命令をフェッチする機構を作りましょう。
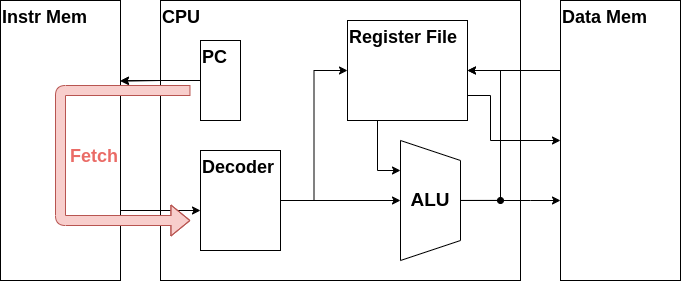
Z16CPU.vに書き込んでいきます。
まずはプログラムカウンタの役割を担うr_pcというレジスタと、フェッチした命令が入力される信号線であるw_instrを新たに定義します。
// プログラムカウンタ
reg [15:0] r_pc;
wire [15:0] w_instr;
次にこのプログラムカウンタを更新する機構を作ります。リセット入力が有効な場合にはこのプログラムカウンタの値を0にし、通常時は2づつカウントアップさせます。
always @(posedge i_clk) begin
if(i_rst) begin
// リセット
r_pc <= 16'h0000;
end else begin
r_pc <= r_pc + 16'h0002;
end
end
続いてプログラムカウンタの値を命令メモリのアドレス入力に接続し、w_instrを命令メモリの出力に接続します。
Z16InstrMem InstrMem(
.i_addr (r_pc ), // プログラムカウンタを命令メモリに接続
.o_instr (w_instr)
);
これで命令フェッチのデータパスは完成です。以下にZ16CPU.vの全体のコードを載せておきます。
module Z16CPU(
input wire i_clk,
input wire i_rst
);
// プログラムカウンタ
reg [15:0] r_pc;
wire [15:0] w_instr;
always @(posedge i_clk) begin
if(i_rst) begin
// リセット
r_pc <= 16'h0000;
end else begin
r_pc <= r_pc + 16'h0002;
end
end
Z16InstrMem InstrMem(
.i_addr (r_pc ), // プログラムカウンタを命令メモリに接続
.o_instr (w_instr)
);
Z16DataMem DataMem(
.i_clk (),
.i_addr (),
.i_wen (),
.i_data (),
.o_data ()
);
endmodule
デコーダの作成
これでフェッチ機構を実装できました。次はフェッチした命令を解釈するデコーダを作成していきましょう。
LOAD命令のビットフィールドは以下のように、LSBから順にオペコード、RDのアドレス、RS1のアドレス、即値となっていましたね。
| instr | [15:12] |
[11:8] |
[7:4] |
[3:0] |
|---|---|---|---|---|
| LOAD命令 | imm[3:0] |
rs1[3:0] |
rd[3:0] |
opcode[3:0] |
オペコード及びRDとRS1のアドレスはそのまま使えるのでスライスを使って取り出しましょう。o_opcodeがオペコード、o_rd_addrがRDのアドレス、o_rs1_addrがRS1のアドレスとなっています。
module Z16Decoder(
input wire [15:0] i_instr, // 命令入力
output wire [3:0] o_opcode, // オペコード出力
output wire [3:0] o_rd_addr, // RDアドレス出力
output wire [3:0] o_rs1_addr // RS1アドレス出力
);
assign o_opcode = i_instr[3:0];
assign o_rd_addr = i_instr[7:4];
assign o_rs1_addr = i_instr[11:8];
endmodule
次に即値ですが、これは命令内で符号付き4bitとなっています。ALUは符号付き16bitの値しか扱えませんので、4bitの値を16bitに変換する必要があります。しかし、4bitの値に12bitの0を結合するだけでは、負の値のおいて以下のような変換ミスが発生します。

よって正の値と負の値で結合する12bitの値を変える符号拡張という処理が必要になります。

そこでデコーダにおいて、命令のオペコードがLOAD命令の場合に即値の符号拡張を行う関数get_imm()を作成します。この関数の中では、連結演算子とビットの繰り返しを組み合わせる事で、符号拡張を実現しています。
function [15:0] get_imm;
input [15:0] i_instr;
begin
case(i_instr[3:0])
4'hA : get_imm = { {12{i_instr[15]}}, i_instr[15:12] };
default : get_imm = 16'h0000;
endcase
end
endfunction
こうして作成した関数を使い、即値のデコード結果を即値出力であるo_immへ入力しましょう。
module Z16Decoder(
input wire [15:0] i_instr,
output wire [3:0] o_opcode,
output wire [3:0] o_rd_addr,
output wire [3:0] o_rs1_addr,
output wire [15:0] o_imm // 即値出力
);
assign o_opcode = i_instr[3:0];
assign o_rd_addr = i_instr[7:4];
assign o_rs1_addr = i_instr[11:8];
assign o_imm = get_imm(i_instr);
// 符号拡張
function [15:0] get_imm;
input [15:0] i_instr;
begin
case(i_instr[3:0])
4'hA : get_imm = { {12{i_instr[15]}}, i_instr[15:12] };
default : get_imm = 16'h0000;
endcase
end
endfunction
endmodule
この次は各モジュールを制御する為の信号を作成していきます。
LOAD命令はメモリから値を読み出し、レジスタファイルに値を書き込む命令でしたね。よってメモリは値を読み出す状態にし、レジスタファイルは値を書き込む状態にする必要があります。そのために、デコーダの出力信号にレジスタファイルの書き込み有効化信号であるo_rd_wenとデータメモリの書き込み有効化信号であるo_mem_wenを追加しましょう。
module Z16Decoder(
input wire [15:0] i_instr,
output wire [3:0] o_opcode,
output wire [3:0] o_rd_addr,
output wire [3:0] o_rs1_addr,
output wire [15:0] o_imm,
output wire o_rd_wen, // レジスタ書き込み有効化信号
output wire o_mem_wen // メモリ書き込み有効化信号
);
LOAD命令の場合、o_rd_wenは1を出力し、o_mem_wenは0を出力する必要がありますね。そのための関数であるget_rd_wen()とget_mem_wen()を作成しましょう。
function get_rd_wen;
input [15:0] i_instr;
begin
if(4'hA == i_instr[3:0]) begin
get_rd_wen = 1'b1;
end else begin
get_rd_wen = 1'b0;
end
end
endfunction
function get_mem_wen;
input [15:0] i_instr;
begin
if(4'hA == i_instr[3:0]) begin
get_mem_wen = 1'b0;
end else begin
get_mem_wen = 1'b0;
end
end
endfunction
こうして作成した関数をデコーダに追加すると以下の通りになります。
module Z16Decoder(
input wire [15:0] i_instr,
output wire [3:0] o_opcode,
output wire [3:0] o_rd_addr,
output wire [3:0] o_rs1_addr,
output wire [15:0] o_imm,
output wire o_rd_wen,
output wire o_mem_wen
);
assign o_opcode = i_instr[3:0];
assign o_rd_addr = i_instr[7:4];
assign o_rs1_addr = i_instr[11:8];
assign o_imm = get_imm(i_instr);
assign o_rd_wen = get_rd_wen(i_instr);
assign o_mem_wen = get_mem_wen(i_instr);
// 符号拡張
function [15:0] get_imm;
input [15:0] i_instr;
begin
case(i_instr[3:0])
4'hA : get_imm = { {12{i_instr[15]}}, i_instr[15:12]};
default : get_imm = 16'h0000;
endcase
end
endfunction
function get_rd_wen;
input [15:0] i_instr;
begin
if(4'hA == i_instr[3:0]) begin
get_rd_wen = 1'b1;
end else begin
get_rd_wen = 1'b0;
end
end
endfunction
function get_mem_wen;
input [15:0] i_instr;
begin
if(4'hA == i_instr[3:0]) begin
get_mem_wen = 1'b0;
end else begin
get_mem_wen = 1'b0;
end
end
endfunction
endmodule
次はALUにアドレス計算を行わせる為に、ALUの制御信号を作成しましょう。まずはALUの制御信号であるo_alu_ctrlを追加します。
module Z16Decoder(
input wire [15:0] i_instr,
output wire [3:0] o_opcode,
output wire [3:0] o_rd_addr,
output wire [3:0] o_rs1_addr,
output wire [15:0] o_imm,
output wire o_rd_wen,
output wire o_mem_wen,
output wire [3:0] o_alu_ctrl // ALU演算制御信号
);
LOAD命令では、即値とRS1の値を加算してアドレスを作っていましたね。
$$ \text{Memory}[\text{IMM} + \text{RS1}] \rightarrow \text{RD} $$
よってALUには加算を行ってもらう必要があります。ALUの実装を見返すとi_ctrlに4'h0を入力すると加算を行ってくれるように実装してありますね。よってLOAD命令のオペコードの場合は4'h0を出力する関数を作成します。
function [3:0] get_alu_ctrl;
input [15:0] i_instr;
begin
if(4'hA == i_instr[3:0]) begin
get_alu_ctrl = 4'h0;
end else begin
get_alu_ctrl = 4'h0;
end
end
endfunction
こうして作成した関数をデコーダに追加すると以下の通りになります。
module Z16Decoder(
input wire [15:0] i_instr,
output wire [3:0] o_opcode,
output wire [3:0] o_rd_addr,
output wire [3:0] o_rs1_addr,
output wire [15:0] o_imm,
output wire o_rd_wen,
output wire o_mem_wen,
output wire [3:0] o_alu_ctrl
);
assign o_opcode = i_instr[3:0];
assign o_rd_addr = i_instr[7:4];
assign o_rs1_addr = i_instr[11:8];
assign o_imm = get_imm(i_instr);
assign o_rd_wen = get_rd_wen(i_instr);
assign o_mem_wen = get_mem_wen(i_instr);
assign o_alu_ctrl = get_alu_ctrl(i_instr);
// 符号拡張
function [15:0] get_imm;
input [15:0] i_instr;
begin
case(i_instr[3:0])
4'hA : get_imm = { {12{i_instr[15]}}, i_instr[15:12]};
default : get_imm = 16'h0000;
endcase
end
endfunction
function get_rd_wen;
input [15:0] i_instr;
begin
if(4'hA == i_instr[3:0]) begin
get_rd_wen = 1'b1;
end else begin
get_rd_wen = 1'b0;
end
end
endfunction
function get_mem_wen;
input [15:0] i_instr;
begin
if(4'hA == i_instr[3:0]) begin
get_mem_wen = 1'b0;
end else begin
get_mem_wen = 1'b0;
end
end
endfunction
function [3:0] get_alu_ctrl;
input [15:0] i_instr;
begin
if(4'hA == i_instr[3:0]) begin
get_alu_ctrl = 4'h0;
end else begin
get_alu_ctrl = 4'h0;
end
end
endfunction
endmodule
これでデコーダが完成しました。CPUに設置し、各種信号線を接続します。
module Z16CPU(
input wire i_clk,
input wire i_rst
);
// Program Counter
reg [15:0] r_pc;
wire [15:0] w_instr;
wire [15:0] w_rd_addr; // RDアドレス信号線
wire [15:0] w_rs1_addr; // RS1アドレス信号線
wire [15:0] w_imm; // 即値信号線
wire w_rd_wen; // レジスタ書き込み有効化信号線
wire w_mem_wen; // メモリ書き込み有効化信号線
wire [3:0] w_alu_ctrl; // ALU演算制御信号線
always @(posedge i_clk) begin
if(i_rst) begin
r_pc <= 16'h0000;
end else begin
r_pc <= r_pc + 16'h0002;
end
end
Z16InstrMemory InstrMem(
.i_addr (r_pc ),
.o_instr (w_instr)
);
Z16Decoder Decoder(
.i_instr (w_instr ),
.o_rd_addr (w_rd_addr ),
.o_rs1_addr (w_rs1_addr ),
.o_imm (w_imm ),
.o_rd_wen (w_rd_wen ),
.o_mem_wen (w_mem_wen ),
.o_alu_ctrl (w_alu_ctrl )
);
Z16DataMemory DataMem(
.i_clk (),
.i_addr (),
.i_wen (),
.i_data (),
.o_data ()
);
endmodule
これで命令をフェッチし、デコーダに命令を入力する所まで実装できました。
レジスタファイルからの値読み出し
次はRS1の値をレジスタから取り出すデータパスを作成しましょう。
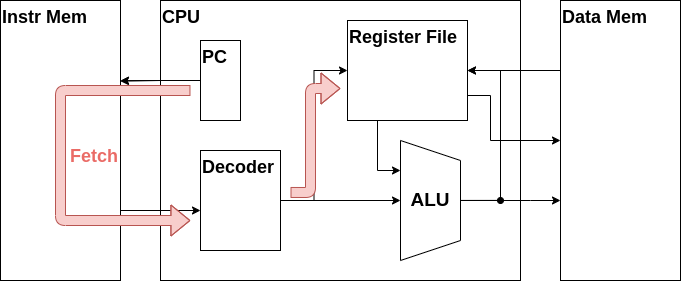
以下ではCPUにレジスタファイルを設置し、デコーダが出力したRS1のアドレスであるw_rs1_addrを接続しています。またRS1のデータの信号線であるw_rs1_dataを新たに定義し、レジスタファイルの出力に接続しています。
module Z16CPU(
input wire i_clk,
input wire i_rst
);
// Program Counter
reg [15:0] r_pc;
wire [15:0] w_instr;
wire [3:0] w_rd_addr;
wire [3:0] w_rs1_addr; // RS1のアドレス
wire [15:0] w_imm;
wire w_rd_wen;
wire w_mem_wen;
wire [3:0] w_alu_ctrl;
wire [15:0] w_rs1_data; // RS1のデータ
always @(posedge i_clk) begin
if(i_rst) begin
r_pc <= 16'h0000;
end else begin
r_pc <= r_pc + 16'h0002;
end
end
Z16InstrMemory InstrMem(
.i_addr (r_pc ),
.o_instr (w_instr)
);
Z16Decoder Decoder(
.i_instr (w_instr ),
.o_rd_addr (w_rd_addr ),
.o_rs1_addr (w_rs1_addr ),
.o_imm (w_imm ),
.o_rd_wen (w_rd_wen ),
.o_mem_wen (w_mem_wen ),
.o_alu_ctrl (w_alu_ctrl )
);
// レジスタファイル
Z16RegisterFile RegFile(
.i_clk (i_clk ),
.i_rs1_addr (w_rs1_addr ), // RS1のアドレスを接続
.o_rs1_data (w_rs1_data ), // RS1のデータを出力
.i_rs2_addr (),
.o_rs2_data (),
.i_rd_data (),
.i_rd_addr (),
.i_rd_wen ()
);
Z16DataMemory DataMem(
.i_clk (),
.i_addr (),
.i_wen (),
.i_data (),
.o_data ()
);
endmodule
アドレス計算
次はアドレス計算を行うデータパスを実装しましょう。
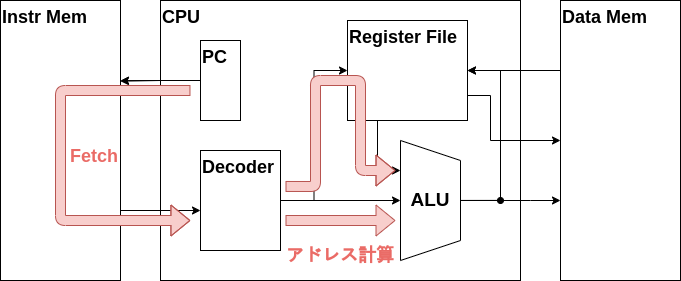
ALUを設置し、w_rs1_data、w_imm、w_alu_ctrlを接続します。またALUの演算結果の信号であるw_alu_dataを新たに定義し、ALUの演算結果出力に接続します。
module Z16CPU(
input wire i_clk,
input wire i_rst
);
// Program Counter
reg [15:0] r_pc;
wire [15:0] w_instr;
wire [3:0] w_rd_addr;
wire [3:0] w_rs1_addr;
wire [15:0] w_imm;
wire w_rd_wen;
wire w_mem_wen;
wire [3:0] w_alu_ctrl;
wire [15:0] w_rs1_data;
wire [15:0] w_alu_data; // ALUの演算結果
always @(posedge i_clk) begin
if(i_rst) begin
r_pc <= 16'h0000;
end else begin
r_pc <= r_pc + 16'h0002;
end
end
Z16InstrMemory InstrMem(
.i_addr (r_pc ),
.o_instr (w_instr)
);
Z16Decoder Decoder(
.i_instr (w_instr ),
.o_rd_addr (w_rd_addr ),
.o_rs1_addr (w_rs1_addr ),
.o_imm (w_imm ),
.o_rd_wen (w_rd_wen ),
.o_mem_wen (w_mem_wen ),
.o_alu_ctrl (w_alu_ctrl )
);
Z16RegisterFile RegFile(
.i_clk (i_clk ),
.i_rs1_addr (w_rs1_addr ),
.o_rs1_data (w_rs1_data ),
.i_rs2_addr (),
.o_rs2_data (),
.i_rd_data (),
.i_rd_addr (),
.i_rd_wen ()
);
// ALU
Z16ALU ALU(
.i_data_a (w_rs1_data ), // RS1のデータを入力
.i_data_b (w_imm ), // 即値を入力
.i_ctrl (w_alu_ctrl ), // ALUの制御信号を入力
.o_data (w_alu_data ) // ALUの演算結果を出力
);
Z16DataMemory DataMem(
.i_clk (),
.i_addr (),
.i_wen (),
.i_data (),
.o_data ()
);
endmodule
メモリからのデータ読み出し
アドレス計算のデータパスが完成したら、次はそのアドレスをメモリに入力し、データを取り出すデータパスを作りましょう。
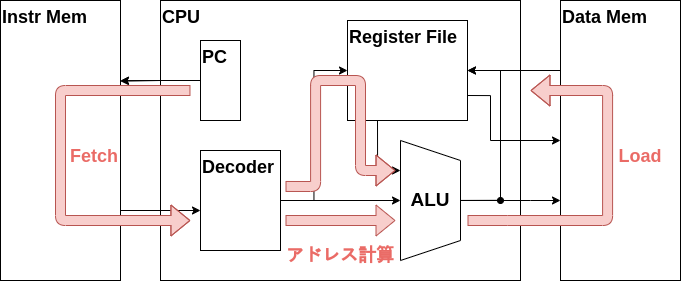
データメモリにALUが計算したアドレスであるw_alu_dataとデコーダからの書き込み有効化信号であるw_mem_wenを接続します。また、メモリから読み出したデータの信号線であるw_mem_rdataを新たに定義し、データメモリに接続します。
module Z16CPU(
input wire i_clk,
input wire i_rst
);
// Program Counter
reg [15:0] r_pc;
wire [15:0] w_instr;
wire [3:0] w_rd_addr;
wire [3:0] w_rs1_addr;
wire [15:0] w_imm;
wire w_rd_wen;
wire w_mem_wen;
wire [3:0] w_alu_ctrl;
wire [15:0] w_rs1_data;
wire [15:0] w_alu_data;
wire [15:0] w_mem_rdata; // メモリからの読み出しデータ
always @(posedge i_clk) begin
if(i_rst) begin
r_pc <= 16'h0000;
end else begin
r_pc <= r_pc + 16'h0002;
end
end
Z16InstrMemory InstrMem(
.i_addr (r_pc ),
.o_instr (w_instr)
);
Z16Decoder Decoder(
.i_instr (w_instr ),
.o_rd_addr (w_rd_addr ),
.o_rs1_addr (w_rs1_addr ),
.o_imm (w_imm ),
.o_rd_wen (w_rd_wen ),
.o_mem_wen (w_mem_wen ),
.o_alu_ctrl (w_alu_ctrl )
);
Z16RegisterFile RegFile(
.i_clk (i_clk ),
.i_rs1_addr (w_rs1_addr ),
.o_rs1_data (w_rs1_data ),
.i_rs2_addr (),
.o_rs2_data (),
.i_rd_data (),
.i_rd_addr (),
.i_rd_wen ()
);
Z16ALU ALU(
.i_data_a (w_rs1_data ),
.i_data_b (w_imm ),
.i_ctrl (w_alu_ctrl ),
.o_data (w_alu_data )
);
Z16DataMemory DataMem(
.i_clk (i_clk ),
.i_addr (w_alu_data ), // アドレス入力
.i_wen (w_mem_wen ), // メモリ書き込み有効化信号
.i_data (),
.o_data (w_mem_rdata) // メモリのデータ出力
);
endmodule
レジスタファイルへのデータ書き込み
最後にメモリから読み出したデータをレジスタファイルに書き込むデータパスを作成しましょう。
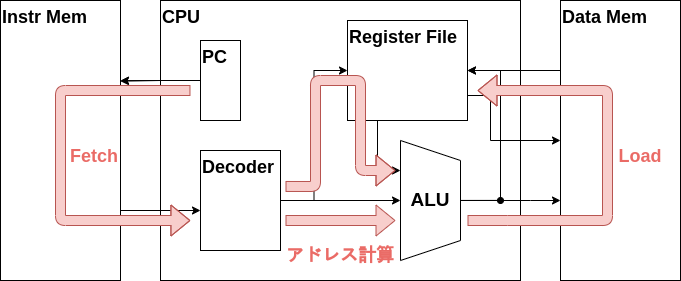
メモリから取り出したデータの信号線であるw_mem_rdataをレジスタファイルのデータ書き込みポートに接続し、またデコーダからのRDのアドレスと書き込み有効化信号を接続します。
module Z16CPU(
input wire i_clk,
input wire i_rst
);
// Program Counter
reg [15:0] r_pc;
wire [15:0] w_instr;
wire [3:0] w_rd_addr;
wire [3:0] w_rs1_addr;
wire [15:0] w_imm;
wire w_rd_wen;
wire w_mem_wen;
wire [3:0] w_alu_ctrl;
wire [15:0] w_rs1_data;
wire [15:0] w_alu_data;
wire [15:0] w_mem_rdata;
always @(posedge i_clk) begin
if(i_rst) begin
r_pc <= 16'h0000;
end else begin
r_pc <= r_pc + 16'h0002;
end
end
Z16InstrMemory InstrMem(
.i_addr (r_pc ),
.o_instr (w_instr)
);
Z16Decoder Decoder(
.i_instr (w_instr ),
.o_rd_addr (w_rd_addr ),
.o_rs1_addr (w_rs1_addr ),
.o_imm (w_imm ),
.o_rd_wen (w_rd_wen ),
.o_mem_wen (w_mem_wen ),
.o_alu_ctrl (w_alu_ctrl )
);
Z16RegisterFile RegFile(
.i_clk (i_clk ),
.i_rs1_addr (w_rs1_addr ),
.o_rs1_data (w_rs1_data ),
.i_rs2_addr (),
.o_rs2_data (),
.i_rd_data (w_mem_rdata),
.i_rd_addr (w_rd_addr ),
.i_rd_wen (w_rd_wen )
);
Z16ALU ALU(
.i_data_a (w_rs1_data ),
.i_data_b (w_imm ),
.i_ctrl (w_alu_ctrl ),
.o_data (w_alu_data )
);
Z16DataMemory DataMem(
.i_clk (i_clk ),
.i_addr (w_alu_data ),
.i_wen (w_mem_wen ),
.i_data (),
.o_data (w_mem_rdata)
);
endmodule
これでLOAD命令のデータパスが完成しました。流石に大変でしたね、LOAD命令が一番データパスが長い命令ですので残りはもっと簡単に実装できます。気を楽にしてください。
このCPUは現在LOAD命令のみを実行できます。シミュレーションで動作を確認してみましょう。
動作の確認
動作を確認するために、まずは命令メモリにLOAD命令を書き込みましょう。以下では命令メモリのアドレス0とアドレス3(正しくは6)にLOAD命令を書き込んであります。それ以外は適当に0で埋めておきましょう。
module Z16InstrMemory(
input wire i_clk,
input wire [15:0] i_addr,
output wire [15:0] o_instr
);
wire [15:0] mem[4:0];
assign o_instr = mem[i_addr[15:1]];
assign mem[0] = 16'h406A; // LOAD 4 ZR G2
assign mem[1] = 16'h0000;
assign mem[2] = 16'h0000;
assign mem[3] = 16'h008A; // LOAD 0 ZR G4
assign mem[4] = 16'h0000;
endmodule
またテストベンチも適当に作成します。最初はリセットをオンにし、2単位時間後にリセットを落としてプログラムの実行を開始するようにしています。
module Z16CPU_tb;
reg i_clk = 1'b0;
reg i_rst = 1'b0;
always #1 begin
i_clk <= ~i_clk;
end
initial begin
$dumpfile("wave.vcd");
$dumpvars(0, Z16CPU_tb);
end
Z16CPU CPU(
.i_clk (i_clk ),
.i_rst (i_rst )
);
initial begin
// リセット
i_rst = 1'b1;
#2
// リセットを落とし、実行開始
i_rst = 1'b0;
#100
$finish;
end
endmodule
以下のコマンドでシミュレーションを実行します。
iverilog Z16CPU_tb.v Z16ALU.v Z16CPU.v Z16DataMemory.v Z16Decoder.v Z16InstrMemory.v Z16RegisterFile.v
vvp a.out
gtkwave wave.vcd
実際にシミュレーションをした結果が以下の波形です。命令メモリから命令をフェッチ、デコーダが各種制御信号を生成、レジスタからの値取り出し、ALUによるアドレス計算、データメモリからの値のロード、レジスタへの値書き込みを行っている様子が分かります。
ただし、値が何も書き込まれていないメモリからデータをロードしているので、レジスタには不定値16'hxxxxが書き込まれている事に注意してください。
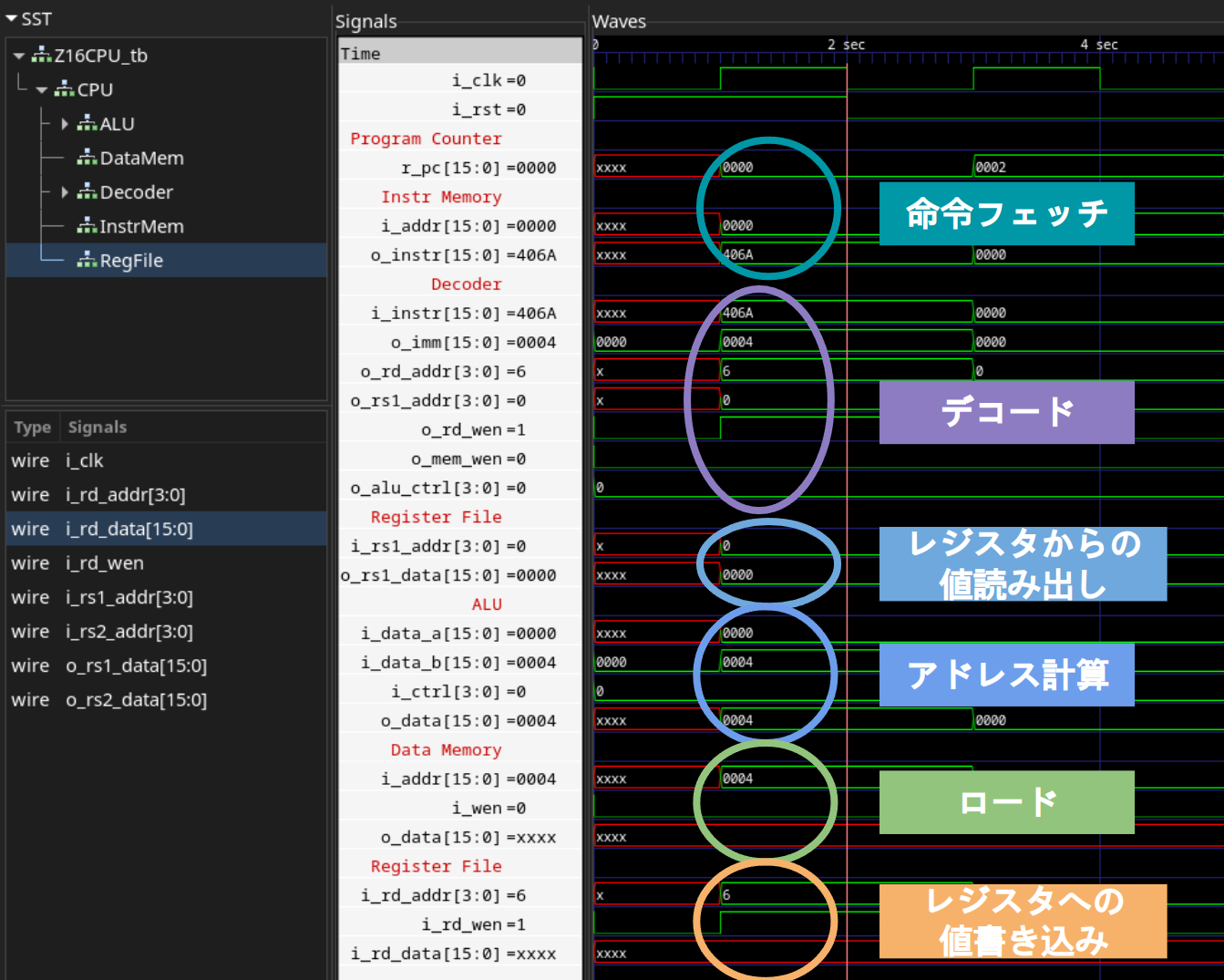
これで、LOAD命令のデータパスが完成した事が確認できました。
Store命令
次はSTORE命令のデータパスを作成し、CPUがSTORE命令を実行できるようにしましょう。
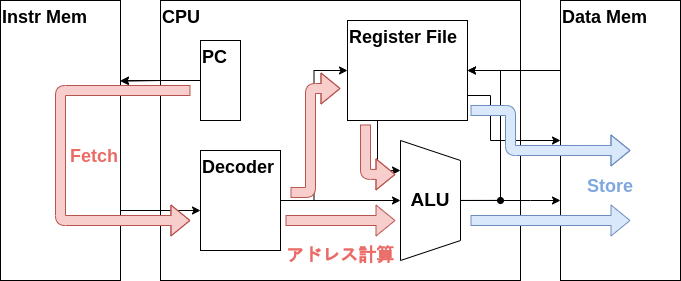
STORE命令の動作を箇条書きすると以下の通りになります。
- 命令メモリから命令をフェッチ
- デコーダが命令を解釈
- レジスタからRS1, RS2の値を取り出す
- ALUでアドレス計算
- データメモリにRS2の値を書き込む
1の命令フェッチの機構はLOAD命令を実装した時に作りましたね。2のデコーダには少し手を加える必要があります。
デコーダを改造
ではデコーダの改造に着手しましょう。
STORE命令のビットフィールドは以下のように、LSBから順にオペコード、即値、RS1のアドレス、RS2のアドレスとなっていましたね。
| instr | [15:12] |
[11:8] |
[7:4] |
[3:0] |
|---|---|---|---|---|
| STORE命令 | rs2[3:0] |
rs1[3:0] |
imm[3:0] |
opcode[3:0] |
LOAD命令のビットフィールドと比較すると、RS1のフィールドは共通ですが、RDのフィールドが即値になり、即値のフィールドがRS2になりました。
RS2のアドレスはそのまま使えるのでスライスを使って取り出しましょう。デコーダの出力として新たにo_rs2_addrを定義し、STORE命令のRS2のアドレスを出力します。
module Z16Decoder(
input wire [15:0] i_instr,
output wire [3:0] o_opcode,
output wire [3:0] o_rd_addr,
output wire [3:0] o_rs1_addr,
output wire [3:0] o_rs2_addr,
output wire [15:0] o_imm,
output wire o_rd_wen,
output wire o_mem_wen,
output wire [3:0] o_alu_ctrl
);
assign o_opcode = i_instr[3:0];
assign o_rd_addr = i_instr[7:4];
assign o_rs1_addr = i_instr[11:8];
assign o_rs2_addr = i_instr[15:12];
assign o_imm = get_imm(i_instr);
assign o_rd_wen = get_rd_wen(i_instr);
assign o_mem_wen = get_mem_wen(i_instr);
assign o_alu_ctrl = get_alu_ctrl(i_instr);
次に即値に対処しましょう。LOAD命令ではi_instrの[15:12]の4bitを取り出し16bitに符号拡張していましたが、STORE命令ではi_instrの[7:4]の4bitが即値となっています。そこでget_immを改造してオペコードがSTORE命令の4'hBの場合はi_instr[7:4]の4bitを取り出して符号拡張するように改造します。
// 符号拡張
function [15:0] get_imm;
input [15:0] i_instr;
begin
case(i_instr[3:0])
4'hA : get_imm = { {12{i_instr[15]}}, i_instr[15:12]};
4'hB : get_imm = { {12{i_instr[7]}}, i_instr[7:4]};
default : get_imm = 16'h0000;
endcase
end
endfunction
次にSTORE命令はメモリに値を書き込む命令ですので、STORE命令が来た時はメモリ書き込み有効化信号であるo_mem_wenを1にする必要があります。Z16において、メモリに値を書き込むのはSTORE命令の場合のみですので、get_mem_wenを改造し、オペコードがSTORE命令の4'hBの場合にのみ1になるようにします。
function get_mem_wen;
input [15:0] i_instr;
begin
// STORE命令の場合にのみ1
if(4'hB == i_instr[3:0]) begin
get_mem_wen = 1'b1;
end else begin
get_mem_wen = 1'b0;
end
end
endfunction
次にALUの制御信号ですが、STORE命令のアドレス計算もRS1と即値の加算ですので、ALUには加算をしてもらう必要があります。
$$ \text{RS2} \rightarrow \text{Memory}[\text{RS1} + \text{IMM}] $$
これはLOAD命令と同じですので、とりあえず今はALUには常に加算をやってもらうように改造します。
function [3:0] get_alu_ctrl;
input [15:0] i_instr;
begin
get_alu_ctrl = 4'h0;
end
endfunction
改造が完了したデコーダは以下の通りです。
module Z16Decoder(
input wire [15:0] i_instr,
output wire [3:0] o_opcode,
output wire [3:0] o_rd_addr,
output wire [3:0] o_rs1_addr,
output wire [3:0] o_rs2_addr,
output wire [15:0] o_imm,
output wire o_rd_wen,
output wire o_mem_wen,
output wire [3:0] o_alu_ctrl
);
assign o_opcode = i_instr[3:0];
assign o_rd_addr = i_instr[7:4];
assign o_rs1_addr = i_instr[11:8];
assign o_rs2_addr = i_instr[15:12];
assign o_imm = get_imm(i_instr);
assign o_rd_wen = get_rd_wen(i_instr);
assign o_mem_wen = get_mem_wen(i_instr);
assign o_alu_ctrl = get_alu_ctrl(i_instr);
// 符号拡張
function [15:0] get_imm;
input [15:0] i_instr;
begin
case(i_instr[3:0])
4'hA : get_imm = { {12{i_instr[15]}}, i_instr[15:12]};
4'hB : get_imm = { {12{i_instr[7]}}, i_instr[7:4]};
default : get_imm = 16'h0000;
endcase
end
endfunction
function get_rd_wen;
input [15:0] i_instr;
begin
if(4'hA == i_instr[3:0]) begin
get_rd_wen = 1'b1;
end else begin
get_rd_wen = 1'b0;
end
end
endfunction
function get_mem_wen;
input [15:0] i_instr;
begin
// STORE命令の場合にのみ1
if(4'hB == i_instr[3:0]) begin
get_mem_wen = 1'b1;
end else begin
get_mem_wen = 1'b0;
end
end
endfunction
function [3:0] get_alu_ctrl;
input [15:0] i_instr;
begin
get_alu_ctrl = 4'h0;
end
endfunction
endmodule
デコーダの改造が完了しましたら、Z16CPU.vにRS2のアドレスの信号線であるw_rs2_addrを追加し、デコーダに接続しましょう。
// Program Counter
reg [15:0] r_pc;
wire [15:0] w_instr;
wire [3:0] w_rd_addr;
wire [3:0] w_rs1_addr;
wire [3:0] w_rs2_addr;
wire [15:0] w_imm;
wire w_rd_wen;
wire w_mem_wen;
wire [3:0] w_alu_ctrl;
中略
Z16Decoder Decoder(
.i_instr (w_instr ),
.o_rd_addr (w_rd_addr ),
.o_rs1_addr (w_rs1_addr ),
.o_rs2_addr (w_rs2_addr ),
.o_imm (w_imm ),
.o_rd_wen (w_rd_wen ),
.o_mem_wen (w_mem_wen ),
.o_alu_ctrl (w_alu_ctrl )
);
レジスタファイルからの値読み出し
次はレジスタファイルからRS2の値を読み出すデータパスを作成しましょう。これで読み出されたRS2の値がメモリに書き込まれる値になります。
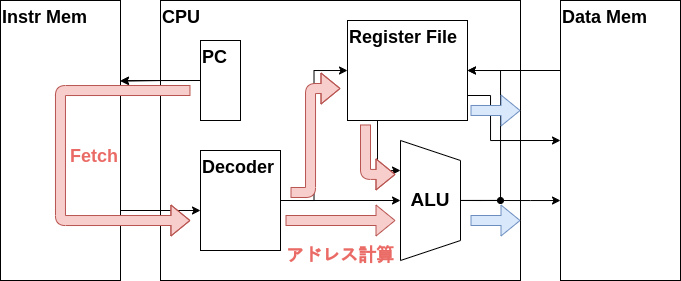
まずはRS2の値の信号線であるw_rs2_dataを新たに定義します。
wire w_mem_wen;
wire [3:0] w_alu_ctrl;
wire [15:0] w_rs1_data;
wire [15:0] w_rs2_data;
wire [15:0] w_alu_data;
wire [15:0] w_mem_rdata;
そしてレジスタファイルのRS2のアドレス入力にはデコーダが出力したw_rs2_addrを接続し、RS2のデータ出力には先程新たに定義したw_rs2_dataを接続します。
Z16RegisterFile RegFile(
.i_clk (i_clk ),
.i_rs1_addr (w_rs1_addr ),
.o_rs1_data (w_rs1_data ),
.i_rs2_addr (w_rs2_addr ),
.o_rs2_data (w_rs2_data ),
.i_rd_data (w_mem_rdata),
.i_rd_addr (w_rd_addr ),
.i_rd_wen (w_rd_wen )
);
これでレジスタファイルからRS2の値を読み出すデータパスが実装できました。ここまでの改造内容をまとめたものが以下になります。
module Z16CPU(
input wire i_clk,
input wire i_rst
);
// Program Counter
reg [15:0] r_pc;
wire [15:0] w_instr;
wire [3:0] w_rd_addr;
wire [3:0] w_rs1_addr;
wire [3:0] w_rs2_addr;
wire [15:0] w_imm;
wire w_rd_wen;
wire w_mem_wen;
wire [3:0] w_alu_ctrl;
wire [15:0] w_rs1_data;
wire [15:0] w_rs2_data;
wire [15:0] w_alu_data;
wire [15:0] w_mem_rdata;
always @(posedge i_clk) begin
if(i_rst) begin
r_pc <= 16'h0000;
end else begin
r_pc <= r_pc + 16'h0002;
end
end
Z16InstrMemory InstrMem(
.i_addr (r_pc ),
.o_instr (w_instr)
);
Z16Decoder Decoder(
.i_instr (w_instr ),
.o_rd_addr (w_rd_addr ),
.o_rs1_addr (w_rs1_addr ),
.o_rs2_addr (w_rs2_addr ),
.o_imm (w_imm ),
.o_rd_wen (w_rd_wen ),
.o_mem_wen (w_mem_wen ),
.o_alu_ctrl (w_alu_ctrl )
);
Z16RegisterFile RegFile(
.i_clk (i_clk ),
.i_rs1_addr (w_rs1_addr ),
.o_rs1_data (w_rs1_data ),
.i_rs2_addr (w_rs2_addr ),
.o_rs2_data (w_rs2_data ),
.i_rd_data (w_mem_rdata),
.i_rd_addr (w_rd_addr ),
.i_rd_wen (w_rd_wen )
);
Z16ALU ALU(
.i_data_a (w_rs1_data ),
.i_data_b (w_imm ),
.i_ctrl (w_alu_ctrl ),
.o_data (w_alu_data )
);
Z16DataMemory DataMem(
.i_clk (i_clk ),
.i_addr (w_alu_data ),
.i_wen (w_mem_wen ),
.i_data (),
.o_data (w_mem_rdata)
);
endmodule
この次のALUでアドレス計算を行うデータパスは、既にLOAD命令を実装する際に完成しているので手を加える必要はありません。
メモリへの値書き込み
最後に、メモリへデータを書き込むデータパスを作成していきます。
レジスタファイルのRS2のデータ出力をデータメモリの書き込みデータ入力に接続します。
module Z16CPU(
input wire i_clk,
input wire i_rst
);
// Program Counter
reg [15:0] r_pc;
wire [15:0] w_instr;
wire [3:0] w_rd_addr;
wire [3:0] w_rs1_addr;
wire [3:0] w_rd_addr;
wire [15:0] w_imm;
wire w_rd_wen;
wire w_mem_wen;
wire [3:0] w_alu_ctrl;
wire [15:0] w_rs1_data;
wire [15:0] w_rs2_data;
wire [15:0] w_alu_data;
wire [15:0] w_mem_rdata;
always @(posedge i_clk) begin
if(i_rst) begin
r_pc <= 16'h0000;
end else begin
r_pc <= r_pc + 16'h0002;
end
end
Z16InstrMemory InstrMem(
.i_addr (r_pc ),
.o_instr (w_instr)
);
Z16Decoder Decoder(
.i_instr (w_instr ),
.o_rd_addr (w_rd_addr ),
.o_rs1_addr (w_rs1_addr ),
.o_rs2_addr (w_rs2_addr ),
.o_imm (w_imm ),
.o_rd_wen (w_rd_wen ),
.o_mem_wen (w_mem_wen ),
.o_alu_ctrl (w_alu_ctrl )
);
Z16RegisterFile RegFile(
.i_clk (i_clk ),
.i_rs1_addr (w_rs1_addr ),
.o_rs1_data (w_rs1_data ),
.i_rs2_addr (w_rs2_addr ),
.o_rs2_data (w_rs2_data ),
.i_rd_data (w_mem_rdata),
.i_rd_addr (w_rd_addr ),
.i_rd_wen (w_rd_wen )
);
Z16ALU ALU(
.i_data_a (w_rs1_data ),
.i_data_b (w_imm ),
.i_ctrl (w_alu_ctrl ),
.o_data (w_alu_data )
);
Z16DataMemory DataMem(
.i_clk (i_clk ),
.i_addr (w_alu_data ),
.i_wen (w_mem_wen ),
.i_data (w_rs2_data ),
.o_data (w_mem_rdata)
);
endmodule
これでSTORE命令のデータパスの実装が完了しました。割と簡単に出来ましたね。これでZ16CPUはLOAD命令とSTORE命令を実行できるようになりました。シミュレーションで動作を確認してみましょう。
動作の確認
動作を確認するために、命令メモリのプログラムを変更しましょう。以下のプログラムはSTORE命令を用いてレジスタZRの値、つまり0をメモリのアドレス4に保存し、次にLOAD命令を用いてメモリのアドレス4に保存されている値をレジスタG1に格納します。つまり実行後に0がレジスタG1が格納されていれば成功という事です。
module Z16InstrMemory(
input wire i_clk,
input wire [15:0] i_addr,
output wire [15:0] o_instr
);
wire [15:0] mem[4:0];
assign o_instr = mem[i_addr[15:1]];
assign mem[0] = 16'h004B; // STORE ZR ZR 4
assign mem[1] = 16'h405A; // LOAD 4 ZR G1
assign mem[2] = 16'h0000;
assign mem[3] = 16'h0000;
assign mem[4] = 16'h0000;
endmodule
テストベンチに変更を行う必要はありません。以下のコマンドでシミュレーションを行い、波形を見ることが出来ます。
iverilog Z16CPU_tb.v Z16ALU.v Z16CPU.v Z16DataMemory.v Z16Decoder.v Z16InstrMemory.v Z16RegisterFile.v
vvp a.out
gtkwave wave.vcd
実際にシミュレーションをした結果が以下の波形です。1サイクル目のSTORE命令でレジスタZRの値をメモリの16'h0004に書き込み、2サイクル目のLOAD命令でメモリの16'h0004の値をレジスタG1に書き込んでいる様子が分かります。
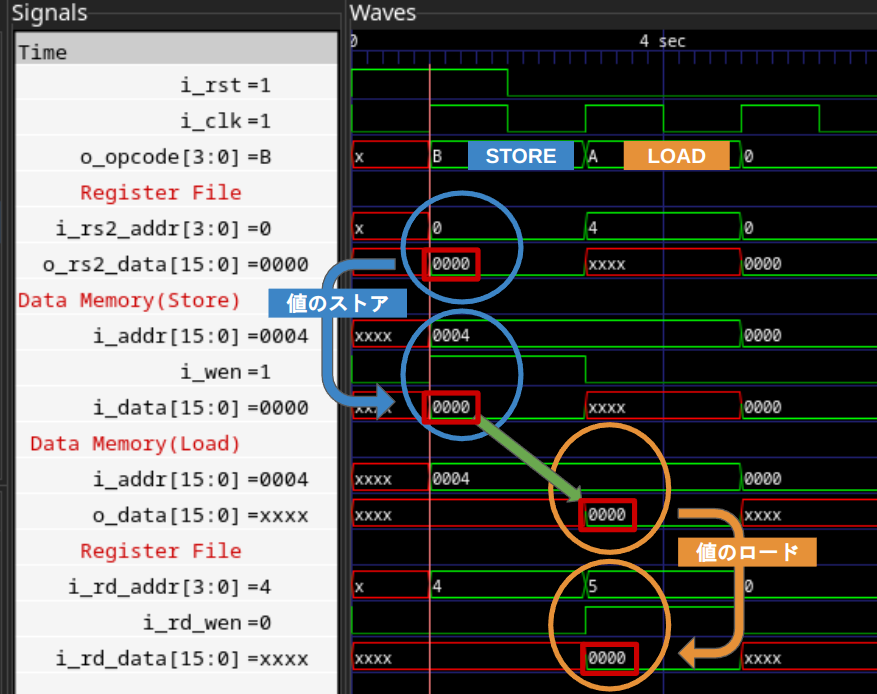
これで、STORE命令のデータパスが完成した事が確認できました。
演算命令
さて、次は演算命令のデータパスを実装し、ADDやSUB、MUL命令などを実行できるようにしましょう。
演算命令の動作を箇条書すると以下の通りになります。
- 命令メモリから命令をフェッチ
- デコーダが命令を解釈
- レジスタからRS1, RS2の値を取り出す
- ALUで演算
- レジスタに演算結果を書き込む
命令フェッチは既に実装してありますので、デコーダの改造に着手しましょう。
デコーダを改造
ではデコーダの改造に着手します。
以下はデコーダの入出力信号です。演算命令を実行するにあたり、変更を加える必要がある信号はレジスタファイルへの書き込み制御信号であるo_rd_wenとALUの制御信号であるo_alu_ctrlです。改造していきましょう。
module Z16Decoder(
input wire [15:0] i_instr,
output wire [3:0] o_opcode,
output wire [3:0] o_rd_addr,
output wire [3:0] o_rs1_addr,
output wire [3:0] o_rs2_addr,
output wire [15:0] o_imm,
output wire o_rd_wen,
output wire o_mem_wen,
output wire [3:0] o_alu_ctrl
);
まずはo_rd_wenに手を加えてきます。Z16において、演算命令が割り当てられているオペコードは4'h0~4'h8でしたね。よってオペコードがこの範囲である場合もo_rd_wenが1になっていればよいという事です。get_rd_wen()を以下のように改造します。
function get_rd_wen;
input [15:0] i_instr;
begin
if(i_instr[3:0] <= 4'h8) begin
get_rd_wen = 1'b1;
end else if(4'hA == i_instr[3:0]) begin
get_rd_wen = 1'b1;
end else begin
get_rd_wen = 1'b0;
end
end
endfunction
次はALUの制御信号であるo_alu_ctrlに手を加えます。ALUの実装を覚えていますでしょうか。本実装では、Z16の演算命令のオペコードとALUの制御信号の値を一致さています。つまり演算命令をALUに実行させたい場合はオペコードをALUに入力すればよいという事です。よってget_alu_ctrl()を改造し、オペコードが演算命令のものの場合はo_alu_ctrlにオペコードの値をそのまま入力するようにします。
function [3:0] get_alu_ctrl;
input [15:0] i_instr;
begin
if(i_instr[3:0] <= 4'h8) begin
get_alu_ctrl = i_instr[3:0];
end else begin
get_alu_ctrl = 4'h0;
end
end
endfunction
以上でデコーダの改造は終わりです。RS1, RS2, RDのアドレスを取り出す機構もLOAD命令とSTORE命令を実装する際に実装できていますので、少しの改造で済みましたね。
以下に改造が完了したデコーダを載せておきます。
module Z16Decoder(
input wire [15:0] i_instr,
output wire [3:0] o_opcode,
output wire [3:0] o_rd_addr,
output wire [3:0] o_rs1_addr,
output wire [3:0] o_rs2_addr,
output wire [15:0] o_imm,
output wire o_rd_wen,
output wire o_mem_wen,
output wire [3:0] o_alu_ctrl
);
assign o_opcode = i_instr[3:0];
assign o_rd_addr = i_instr[7:4];
assign o_rs1_addr = i_instr[11:8];
assign o_rs2_addr = i_instr[15:12];
assign o_imm = get_imm(i_instr);
assign o_rd_wen = get_rd_wen(i_instr);
assign o_mem_wen = get_mem_wen(i_instr);
assign o_alu_ctrl = get_alu_ctrl(i_instr);
// 符号拡張
function [15:0] get_imm;
input [15:0] i_instr;
begin
case(i_instr[3:0])
4'hA : get_imm = { {12{i_instr[15]}}, i_instr[15:12]};
4'hB : get_imm = { {12{i_instr[7]}}, i_instr[7:4]};
default : get_imm = 16'h0000;
endcase
end
endfunction
function get_rd_wen
input [15:0] i_instr;
begin
if(i_instr[3:0] <= 4'h8) begin
get_rd_wen = 1'b1;
end else if(4'hA == i_instr[3:0]) begin
get_rd_wen = 1'b1;
end else begin
get_rd_wen = 1'b0;
end
end
endfunction
function get_mem_wen;
input [15:0] i_instr;
begin
// STORE命令の場合にのみ1
if(4'hB == i_instr[3:0]) begin
get_mem_wen = 1'b1;
end else begin
get_mem_wen = 1'b0;
end
end
endfunction
function [3:0] get_alu_ctrl;
input [15:0] i_instr;
begin
if(i_instr[3:0] <= 4'h8) begin
get_alu_ctrl = i_instr[3:0];
end else begin
get_alu_ctrl = 4'h0;
end
end
endfunction
endmodule
ALUで演算
デコーダの改造が完了したら次はALUで演算を行うデータパスを実装しましょう。
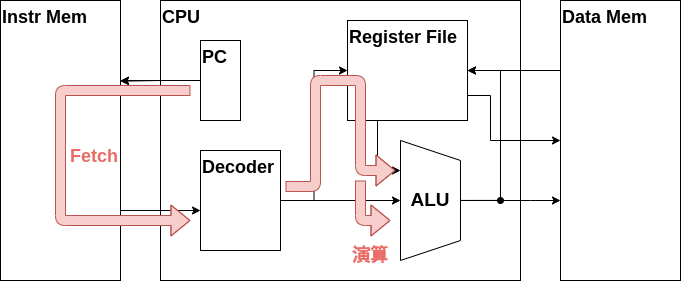
現状のZ16CPU.vの実装を見てみると、ALUのデータ入力にはw_rs1_dataとw_immが入力されています。演算命令はw_rs1_dataとw_rs2_dataの値で演算を行う命令ですので、ALUにw_rs2_dataを接続する必要があります。しかしながらw_immをw_rs2_dataに置き換えるだけでは先程実装したLOAD命令とSTORE命令が実行できなくなります。そこで、フェッチされた命令によってALUのi_data_bに入力される信号が変わるようにしましょう。
Z16ALU ALU(
.i_data_a (w_rs1_data ),
.i_data_b (w_imm ),
.i_ctrl (w_alu_ctrl ),
.o_data (w_alu_data )
);
まずはw_opcodeとw_data_bという信号線をZ16CPU.vに新たに定義します。
wire w_mem_wen;
wire [3:0] w_alu_ctrl;
wire [3:0] w_opcode;
wire [15:0] w_rs1_data;
wire [15:0] w_rs2_data;
wire [15:0] w_data_b;
wire [15:0] w_alu_data;
そしてデコーダにある今まで使ってこなかった信号線であるo_opcodeの出力信号をw_opcodeに接続します。
Z16Decoder Decoder(
.i_instr (w_instr ),
.o_opcode (w_opcode ),
.o_rd_addr (w_rd_addr ),
.o_rs1_addr (w_rs1_addr ),
.o_rs2_addr (w_rs2_addr ),
.o_imm (w_imm ),
.o_rd_wen (w_rd_wen ),
.o_mem_wen (w_mem_wen ),
.o_alu_ctrl (w_alu_ctrl )
);
そしてw_opcodeの値を利用して、w_opcodeが演算命令の場合はw_data_bにw_rs2_data値が入力され、それ以外の場合はw_immの値が入力されるようにします。
assign w_data_b = (w_opcode <= 8'h8) ? w_rs2_data : w_imm;
Z16ALU ALU(
.i_data_a (w_rs1_data ),
.i_data_b (w_data_b ),
.i_ctrl (w_alu_ctrl ),
.o_data (w_alu_data )
);
レジスタへの演算結果書き込み
あと残っているのはレジスタファイルへの演算結果の書き込みのデータパスです。やっていきましょう。
レジスタファイルへの値書き込みですが、現状のZ16CPU.vの実装を見てみると、レジスタファイルのデータ入力であるi_rd_dataにはメモリからのデータ信号であるw_mem_rdataが直接接続されていますね。これではALUの演算結果をレジスタに書き込めません。
Z16RegisterFile RegFile(
.i_clk (i_clk ),
.i_rs1_addr (w_rs1_addr ),
.o_rs1_data (w_rs1_data ),
.i_rs2_addr (w_rs2_addr ),
.o_rs2_data (w_rs2_data ),
.i_rd_data (w_mem_rdata),
.i_rd_addr (w_rd_addr ),
.i_rd_wen (w_rd_wen )
);
よって対応が必要になります。まずはレジスタファイルへの書き込みデータ信号線であるw_rd_dataを新たに定義し、レジスタファイルのデータ書き込みに接続しましょう。
wire [15:0] w_rs1_data;
wire [15:0] w_rs2_data;
wire [15:0] w_rd_data;
wire [15:0] w_data_b;
wire [15:0] w_alu_data;
そしたら以下のようにi_rd_dataにw_rd_dataを接続し、フェッチされた命令がLOAD命令の場合はw_mem_rdataがw_rd_addrに入力され、それ以外の場合はw_alu_dataが入力されるようにします。
assign w_rd_data = (w_opcode[3:0] == 4'hA) ? w_mem_rdata : w_alu_data;
Z16RegisterFile RegFile(
.i_clk (i_clk ),
.i_rs1_addr (w_rs1_addr ),
.o_rs1_data (w_rs1_data ),
.i_rs2_addr (w_rs2_addr ),
.o_rs2_data (w_rs2_data ),
.i_rd_data (w_rd_data ),
.i_rd_addr (w_rd_addr ),
.i_rd_wen (w_rd_wen )
);
これで演算命令のデータバスの実装が完了しました。全体のコードが以下の通りです。
module Z16CPU(
input wire i_clk,
input wire i_rst
);
// Program Counter
reg [15:0] r_pc;
wire [15:0] w_instr;
wire [3:0] w_rd_addr;
wire [3:0] w_rs1_addr;
wire [3:0] w_rs2_addr;
wire [15:0] w_imm;
wire w_rd_wen;
wire w_mem_wen;
wire [3:0] w_alu_ctrl;
wire [3:0] w_opcode;
wire [15:0] w_rs1_data;
wire [15:0] w_rs2_data;
wire [15:0] w_rd_data;
wire [15:0] w_data_b;
wire [15:0] w_alu_data;
wire [15:0] w_mem_rdata;
always @(posedge i_clk) begin
if(i_rst) begin
r_pc <= 16'h0000;
end else begin
r_pc <= r_pc + 16'h0002;
end
end
Z16InstrMemory InstrMem(
.i_addr (r_pc ),
.o_instr (w_instr)
);
Z16Decoder Decoder(
.i_instr (w_instr ),
.o_opcode (w_opcode ),
.o_rd_addr (w_rd_addr ),
.o_rs1_addr (w_rs1_addr ),
.o_rs2_addr (w_rs2_addr ),
.o_imm (w_imm ),
.o_rd_wen (w_rd_wen ),
.o_mem_wen (w_mem_wen ),
.o_alu_ctrl (w_alu_ctrl )
);
assign w_rd_data = (w_opcode[3:0] == 4'hA) ? w_mem_rdata : w_alu_data;
Z16RegisterFile RegFile(
.i_clk (i_clk ),
.i_rs1_addr (w_rs1_addr ),
.o_rs1_data (w_rs1_data ),
.i_rs2_addr (w_rs2_addr ),
.o_rs2_data (w_rs2_data ),
.i_rd_data (w_rd_data ),
.i_rd_addr (w_rd_addr ),
.i_rd_wen (w_rd_wen )
);
assign w_data_b = (w_opcode <= 8'h8) ? w_rs2_data : w_imm;
Z16ALU ALU(
.i_data_a (w_rs1_data ),
.i_data_b (w_data_b ),
.i_ctrl (w_alu_ctrl ),
.o_data (w_alu_data )
);
Z16DataMemory DataMem(
.i_clk (i_clk ),
.i_addr (w_alu_data ),
.i_wen (w_mem_wen ),
.i_data (w_rs2_data ),
.o_data (w_mem_rdata)
);
endmodule
動作の確認は次の即値命令を実装してからにしましょう
即値命令
続いて即値命令のデータパスを実装しましょう。
即値命令の動作を箇条書きすると以下の通りになります。
- 命令メモリから命令をフェッチ
- デコーダが命令を解釈
- レジスタからRDの値を取り出す
- ALUで演算
- レジスタに演算結果を書き込む
デコーダを改造
ではデコーダの改造に着手します。
Z16の即値命令であるADDIは、RDの値に即値を加算してRDに格納する命令でした。
$$ \text{IMM} + \text{RD} \rightarrow \text{RD} $$
現状、レジスタファイルから値を読み出すにはo_rs1_addrかo_rs2_addrにアドレスを入力する必要があります。そこで今回はRDの値をRS1のポートから取り出す事にします。
そのため、get_rs1_addr()という関数を新たに定義し、即値命令のオペコードの場合はo_rs1_addrにRDのアドレスを入力し、それ以外の場合はRS1のアドレスを入力するようにします。
assign o_opcode = i_instr[3:0];
assign o_rd_addr = i_instr[7:4];
assign o_rs1_addr = get_rs1_addr(i_instr);
assign o_rs2_addr = i_instr[15:12];
assign o_imm = get_imm(i_instr);
assign o_rd_wen = get_rd_wen(i_instr);
assign o_mem_wen = get_mem_wen(i_instr);
assign o_alu_ctrl = get_alu_ctrl(i_instr);
function [3:0] get_rs1_addr;
input [15:0] i_instr;
begin
case(i_instr[3:0])
4'h9 : get_rs1_addr = i_instr[7:4];
default : get_rs1_addr = i_instr[11:8];
endcase
end
endfunction
次に即値に対処します。ADDIのビットフィールドには、[15:8]に符号付き8bitの即値が存在していました。
| instr | [15:8] |
[7:4] |
[3:0] |
|---|---|---|---|
| 即値命令 | imm[7:0] |
rd[3:0] |
opcode[3:0] |
デコーダのget_imm()を改造し、ADDI命令の場合は符号付き8bitの即値を16bitに符号拡張するようにしましょう。
// 符号拡張
function [15:0] get_imm;
input [15:0] i_instr;
begin
case(i_instr[3:0])
4'h9 : get_imm = { {8{i_instr[15]}}, i_instr[15:8]};
4'hA : get_imm = { {12{i_instr[15]}}, i_instr[15:12]};
4'hB : get_imm = { {12{i_instr[7]}}, i_instr[7:4]};
default : get_imm = 16'h0000;
endcase
end
endfunction
そして、ADDI命令は演算命令と同じくレジスタファイルに値を書き込む命令ですので、get_rd_wen()を改造し、ADDI命令の場合はo_rd_wenを1にするようにします。
function get_rd_wen;
input [15:0] i_instr;
begin
if(i_instr[3:0] <= 4'h8) begin
get_rd_wen = 1'b1;
end else if(4'h9 == i_instr[3:0]) begin
get_rd_wen = 1'b1;
end else if(4'hA == i_instr[3:0]) begin
get_rd_wen = 1'b1;
end else begin
get_rd_wen = 1'b0;
end
end
endfunction
上記の記述だと冗長ですので、以下のように纏めてしまいましょう。
function get_rd_wen;
input [15:0] i_instr;
begin
if(i_instr[3:0] <= 4'hA) begin
get_rd_wen = 1'b1;
end else begin
get_rd_wen = 1'b0;
end
end
endfunction
またALUの制御信号ですが、即値命令はADDIだけであり、既に演算命令以外ではALUに加算を行わせるようにしていますので、get_alu_ctrl()の改造の必要はありません。
function [3:0] get_alu_ctrl;
input [15:0] i_instr;
begin
if(i_instr[3:0] <= 4'h8) begin
get_alu_ctrl = i_instr[3:0];
end else begin
get_alu_ctrl = 4'h0;
end
end
endfunction
これでデコーダの改造が完了しました。改造が完了したデコーダを以下に載せておきます。
module Z16Decoder(
input wire [15:0] i_instr,
output wire [3:0] o_opcode,
output wire [3:0] o_rd_addr,
output wire [3:0] o_rs1_addr,
output wire [3:0] o_rs2_addr,
output wire [15:0] o_imm,
output wire o_rd_wen,
output wire o_mem_wen,
output wire [3:0] o_alu_ctrl
);
assign o_opcode = i_instr[3:0];
assign o_rd_addr = i_instr[7:4];
assign o_rs1_addr = get_rs1_addr(i_instr);
assign o_rs2_addr = i_instr[15:12];
assign o_imm = get_imm(i_instr);
assign o_rd_wen = get_rd_wen(i_instr);
assign o_mem_wen = get_mem_wen(i_instr);
assign o_alu_ctrl = get_alu_ctrl(i_instr);
function [3:0] get_rs1_addr;
input [15:0] i_instr;
begin
case(i_instr[3:0])
4'h9 : get_rs1_addr = i_instr[7:4];
default : get_rs1_addr = i_instr[11:8];
endcase
end
endfunction
// 符号拡張
function [15:0] get_imm;
input [15:0] i_instr;
begin
case(i_instr[3:0])
4'h9 : get_imm = { {8{i_instr[15]}}, i_instr[15:8]};
4'hA : get_imm = { {12{i_instr[15]}}, i_instr[15:12]};
4'hB : get_imm = { {12{i_instr[7]}}, i_instr[7:4]};
default : get_imm = 16'h0000;
endcase
end
endfunction
function get_rd_wen;
input [15:0] i_instr;
begin
if(i_instr[3:0] <= 4'hA) begin
get_rd_wen = 1'b1;
end else begin
get_rd_wen = 1'b0;
end
end
endfunction
function get_mem_wen;
input [15:0] i_instr;
begin
// STORE命令の場合にのみ1
if(4'hB == i_instr[3:0]) begin
get_mem_wen = 1'b1;
end else begin
get_mem_wen = 1'b0;
end
end
endfunction
function [3:0] get_alu_ctrl;
input [15:0] i_instr;
begin
if(i_instr[3:0] <= 4'h8) begin
get_alu_ctrl = i_instr[3:0];
end else begin
get_alu_ctrl = 4'h0;
end
end
endfunction
endmodule
実はデコーダの改造が完了した時点で、即値命令のデータパスの実装は完了しています。今までの実装が生きましたね。
動作の確認
それでは先程実装した演算命令と即値命令の動作確認を行っていきましょう。
動作確認用のプログラムとして、ADDIの説明の際に用いたサンプルプログラムを改造して使いましょう。
$$ \begin{align} x &= 120 \\ y &= 87 \\ f(x, y) &= 3\times x + 100 + y \end{align} $$
以下のプログラムはG0とG1とG4を0で初期化した後、G0に120を格納、G1に87を格納して計算を行い、計算結果をメモリのアドレス0に格納しています。
ADD ZR ZR G0
ADD ZR ZR G1
ADD ZR ZR G4
ADDI 120 G0
ADDI 87 G1
ADDI 3 G4
MUL G4 G0 G2
ADDI 100 G1
ADD G2 G1 G7
STORE G7 ZR 0
このプログラムをアセンブルしてバイナリを命令メモリに格納します。
module Z16InstrMemory(
input wire i_clk,
input wire [15:0] i_addr,
output wire [15:0] o_instr
);
wire [15:0] mem[10:0];
assign o_instr = mem[i_addr[15:1]];
assign mem[0] = 16'h0040; // ADD ZR ZR G0
assign mem[1] = 16'h0050; // ADD ZR ZR G1
assign mem[2] = 16'h0080; // ADD ZR ZR G4
assign mem[3] = 16'h7849; // ADDI 120 G0
assign mem[4] = 16'h5759; // ADDI 87 G1
assign mem[5] = 16'h0389; // ADDI 3 G4
assign mem[6] = 16'h8462; // MUL G4 G0 G2
assign mem[7] = 16'h6459; // ADDI 100 G1
assign mem[8] = 16'h65B0; // ADD G2 G1 G7
assign mem[9] = 16'hB00B; // STORE G7 ZR 0
assign mem[10] = 16'h0000;
endmodule
テストベンチに変更を行う必要はありません。以下のコマンドでシミュレーションを行い、波形を見ることが出来ます。
iverilog Z16CPU_tb.v Z16ALU.v Z16CPU.v Z16DataMemory.v Z16Decoder.v Z16InstrMemory.v Z16RegisterFile.v
vvp a.out
gtkwave wave.vcd
以下の波形が実際にシミュレーションを行った結果です。データメモリの信号を見てみると、後半にメモリのアドレス0に16進数で16'h0223が書き込まれています。
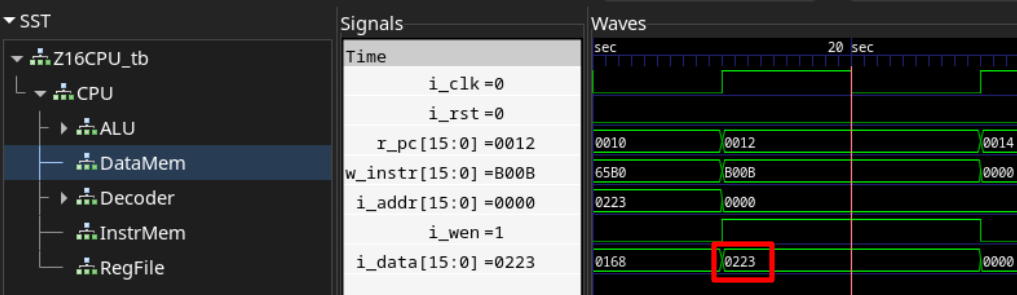
これを10進数に直すと547であり、上記の数式の計算結果と一致しています。
これで我々のCPUは演算命令と即値命令を実行できることが確認できました。やったね。
ジャンプ命令
どんどん行きましょう。次はジャンプ命令のデータパスを作成していきます。
ジャンプ命令の動作を箇条書すると以下の通りになります。
- 命令メモリから命令をフェッチ
- デコーダが命令を解釈
- レジスタからRS1の値を読み出し
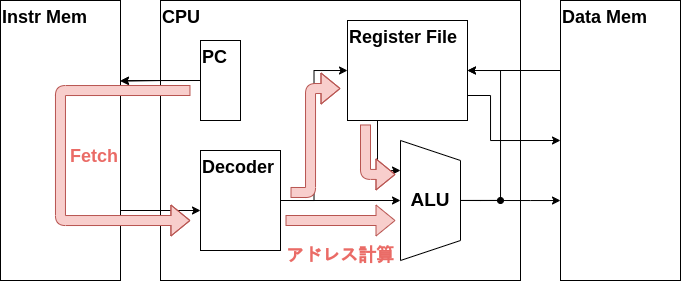
- ALUでジャンプ先アドレスを計算
- レジスタにPC + 2の値を書き込み
- PCに書き込み
やることは変わりません。まずはデコーダを改造しましょう。
デコーダの改造
ではデコーダの改造に着手します。
ジャンプ命令のビットフィールドは以下のように、MSBから4bitに符号付き4bit即値が存在しています。
| instr | [15:12] |
[11:8] |
[7:4] |
[3:0] |
|---|---|---|---|---|
| ジャンプ命令 | imm[3:0] |
rs1[3:0] |
rd[3:0] |
opcode[3:0] |
この符号付き4bitを符号付き16bitに符号拡張してやる必要があります。という訳でデコーダのget_imm()を改造してジャンプ命令の場合にw_instr[15:12]を符号拡張するようにしましょう。
// 符号拡張
function [15:0] get_imm;
input [15:0] i_instr;
begin
case(i_instr[3:0])
4'h9 : get_imm = { {8{i_instr[15]}}, i_instr[15:8]};
4'hA : get_imm = { {12{i_instr[15]}}, i_instr[15:12]};
4'hB : get_imm = { {12{i_instr[7]}}, i_instr[7:4]};
4'hC : get_imm = { {12{i_instr[15]}}, i_instr[15:12]};
4'hD : get_imm = { {12{i_instr[15]}}, i_instr[15:12]};
default : get_imm = 16'h0000;
endcase
end
endfunction
ジャンプ命令のJALとJRLの両方ともRDにPC + 2の値を格納する動作をしますので、ジャンプ命令のオペコードの場合はw_rd_wenを1にする必要があります。
- JAL
$$ \begin{align} \text{PC} + 2 &\rightarrow \text{RD} \\ \text{IMM} + \text{RS1} &\rightarrow \text{PC} \end{align} $$
- JRL
$$ \begin{align} \text{PC} + 2 &\rightarrow \text{RD} \\ \text{IMM} + \text{RS1} + \text{PC} &\rightarrow \text{PC} \end{align} $$
よってget_rd_wen()を改造して対応します。
function get_rd_wen;
input [15:0] i_instr;
begin
if(i_instr[3:0] <= 4'hA) begin
get_rd_wen = 1'b1;
end else if((i_instr[3:0] == 4'hC) || (i_instr[3:0] == 4'hD)) begin
get_rd_wen = 1'b1;
end else begin
get_rd_wen = 1'b0;
end
end
endfunction
get_mem_wen()に関しては、ジャンプ命令はメモリに値を書き込みませんので手を加える必要はありません。またget_alu_ctrl()に関しては、ジャンプ命令先のアドレス計算には加算しか用いませんので、従来の演算命令以外は0を返す実装に手を加える必要はありません。
よってALUでジャンプ先のアドレスを計算するデータパスまでは完成しました。
以下に改造が完了したデコーダの全体を載せておきます。
module Z16Decoder(
input wire [15:0] i_instr,
output wire [3:0] o_opcode,
output wire [3:0] o_rd_addr,
output wire [3:0] o_rs1_addr,
output wire [3:0] o_rs2_addr,
output wire [15:0] o_imm,
output wire o_rd_wen,
output wire o_mem_wen,
output wire [3:0] o_alu_ctrl
);
assign o_opcode = i_instr[3:0];
assign o_rd_addr = i_instr[7:4];
assign o_rs1_addr = get_rs1_addr(i_instr);
assign o_rs2_addr = i_instr[15:12];
assign o_imm = get_imm(i_instr);
assign o_rd_wen = get_rd_wen(i_instr);
assign o_mem_wen = get_mem_wen(i_instr);
assign o_alu_ctrl = get_alu_ctrl(i_instr);
function [3:0] get_rs1_addr;
input [15:0] i_instr;
begin
case(i_instr[3:0])
4'h9 : get_rs1_addr = i_instr[7:4];
default : get_rs1_addr = i_instr[11:8];
endcase
end
endfunction
// 符号拡張
function [15:0] get_imm;
input [15:0] i_instr;
begin
case(i_instr[3:0])
4'h9 : get_imm = { {8{i_instr[15]}}, i_instr[15:8]};
4'hA : get_imm = { {12{i_instr[15]}}, i_instr[15:12]};
4'hB : get_imm = { {12{i_instr[7]}}, i_instr[7:4]};
4'hC : get_imm = { {12{i_instr[15]}}, i_instr[15:12]};
4'hD : get_imm = { {12{i_instr[15]}}, i_instr[15:12]};
default : get_imm = 16'h0000;
endcase
end
endfunction
function get_rd_wen;
input [15:0] i_instr;
begin
if(i_instr[3:0] <= 4'hA) begin
get_rd_wen = 1'b1;
end else if((i_instr[3:0] == 4'hC) || (i_instr[3:0] == 4'hD)) begin
get_rd_wen = 1'b1;
end else begin
get_rd_wen = 1'b0;
end
end
endfunction
function get_mem_wen;
input [15:0] i_instr;
begin
// STORE命令の場合にのみ1
if(4'hB == i_instr[3:0]) begin
get_mem_wen = 1'b1;
end else begin
get_mem_wen = 1'b0;
end
end
endfunction
function [3:0] get_alu_ctrl;
input [15:0] i_instr;
begin
if(i_instr[3:0] <= 4'h8) begin
get_alu_ctrl = i_instr[3:0];
end else begin
get_alu_ctrl = 4'h0;
end
end
endfunction
endmodule
レジスタにPC + 2の値を格納
次はレジスタのRDにPC + 2の値を格納するデータパスを実装しましょう。
従来のデータパスでは、RDに格納する値はLOAD命令でメモリから読み出したデータのw_mem_rdataか、演算命令か即値命令で計算したw_alu_dataでした。ここにジャンプ命令のオペコードの場合はPC + 2の値を格納するようにする必要があります。
assign w_rd_data = (w_opcode == 4'hA) ? w_mem_rdata : w_alu_data;
Z16RegisterFile RegFile(
.i_clk (i_clk ),
.i_rs1_addr (w_rs1_addr ),
.o_rs1_data (w_rs1_data ),
.i_rs2_addr (w_rs2_addr ),
.o_rs2_data (w_rs2_data ),
.i_rd_data (w_rd_data ),
.i_rd_addr (w_rd_addr ),
.i_rd_wen (w_rd_wen )
);
そこで新たな関数であるselect_rd_data()を定義し、オペコードによってRDに格納するデータを決められるようにしましょう。
オペコードがLOAD命令の場合はw_mem_rdataを入力し、ジャンプ命令の場合はr_pc + 16'h0002の値を入力し、それ以外の場合はw_alu_dataの値を入力するようにします。
assign w_rd_data = select_rd_data(w_opcode, w_mem_rdata, r_pc, w_alu_data);
function [15:0] select_rd_data;
input [3:0] i_opcode;
input [15:0] i_mem_rdata;
input [15:0] i_pc;
input [15:0] i_alu_data;
begin
case(i_opcode)
4'hA : select_rd_data = i_mem_rdata;
4'hC : select_rd_data = i_pc + 16'h0002;
4'hD : select_rd_data = i_pc + 16'h0002;
default : select_rd_data = i_alu_data;
endcase
end
endfunction
Z16RegisterFile RegFile(
.i_clk (i_clk ),
.i_rs1_addr (w_rs1_addr ),
.o_rs1_data (w_rs1_data ),
.i_rs2_addr (w_rs2_addr ),
.o_rs2_data (w_rs2_data ),
.i_rd_data (w_rd_data ),
.i_rd_addr (w_rd_addr ),
.i_rd_wen (w_rd_wen )
);
PCにジャンプ先のアドレス書き込み
次にプログラムカウンタにジャンプ先のアドレスを書き込む機構を実装します。
今まではr_pcに対してリセット時以外はひたすらカウントアップしていく機構が組まれていましたが、ここにジャンプ命令のオペコードに対応してr_pcの値を変更する機構を追加します。
always @(posedge i_clk) begin
if(i_rst) begin
r_pc <= 16'h0000;
end else if(w_opcode == 4'hC) begin // JAL
r_pc <= w_alu_data;
end else if(w_opcode == 4'hD) begin // JRL
r_pc <= r_pc + w_alu_data;
end else begin
r_pc <= r_pc + 16'h0002;
end
end
JALの場合は絶対ジャンプなのでALUの計算結果を直接入力し、JRLは相対ジャンプなのでALUの計算結果をPCの値に加算しています。
これでジャンプ命令のデータパスの実装が完了しました。全体のコードを以下に載せておきます。
module Z16CPU(
input wire i_clk,
input wire i_rst
);
// Program Counter
reg [15:0] r_pc;
wire [15:0] w_instr;
wire [3:0] w_rd_addr;
wire [3:0] w_rs1_addr;
wire [3:0] w_rs2_addr;
wire [15:0] w_imm;
wire w_rd_wen;
wire w_mem_wen;
wire [3:0] w_alu_ctrl;
wire [3:0] w_opcode;
wire [15:0] w_rs1_data;
wire [15:0] w_rs2_data;
wire [15:0] w_rd_data;
wire [15:0] w_data_b;
wire [15:0] w_alu_data;
wire [15:0] w_mem_rdata;
always @(posedge i_clk) begin
if(i_rst) begin
r_pc <= 16'h0000;
end else if(w_opcode == 4'hC) begin // JAL
r_pc <= w_alu_data;
end else if(w_opcode == 4'hD) begin // JRL
r_pc <= r_pc + w_alu_data;
end else begin
r_pc <= r_pc + 16'h0002;
end
end
Z16InstrMemory InstrMem(
.i_addr (r_pc ),
.o_instr (w_instr)
);
Z16Decoder Decoder(
.i_instr (w_instr ),
.o_opcode (w_opcode ),
.o_rd_addr (w_rd_addr ),
.o_rs1_addr (w_rs1_addr ),
.o_rs2_addr (w_rs2_addr ),
.o_imm (w_imm ),
.o_rd_wen (w_rd_wen ),
.o_mem_wen (w_mem_wen ),
.o_alu_ctrl (w_alu_ctrl )
);
assign w_rd_data = select_rd_data(w_opcode, w_mem_rdata, r_pc, w_alu_data);
function [15:0] select_rd_data;
input [3:0] i_opcode;
input [15:0] i_mem_rdata;
input [15:0] i_pc;
input [15:0] i_alu_data;
begin
case(i_opcode)
4'hA : select_rd_data = i_mem_rdata;
4'hC : select_rd_data = r_pc + 16'h0002;
4'hD : select_rd_data = r_pc + 16'h0002;
default : select_rd_data = i_alu_data;
endcase
end
endfunction
Z16RegisterFile RegFile(
.i_clk (i_clk ),
.i_rs1_addr (w_rs1_addr ),
.o_rs1_data (w_rs1_data ),
.i_rs2_addr (w_rs2_addr ),
.o_rs2_data (w_rs2_data ),
.i_rd_data (w_rd_data ),
.i_rd_addr (w_rd_addr ),
.i_rd_wen (w_rd_wen )
);
assign w_data_b = (w_opcode <= 8'h8) ? w_rs2_data : w_imm;
Z16ALU ALU(
.i_data_a (w_rs1_data ),
.i_data_b (w_data_b ),
.i_ctrl (w_alu_ctrl ),
.o_data (w_alu_data )
);
Z16DataMemory DataMem(
.i_clk (i_clk ),
.i_addr (w_alu_data ),
.i_wen (w_mem_wen ),
.i_data (w_rs2_data ),
.o_data (w_mem_rdata)
);
endmodule
動作の確認に移りましょう。
動作の確認
動作の確認を行うための以下のテストプログラムを使います。
0: ADD ZR ZR G0
2: JRL 6 ZR G1
4: ADD ZR ZR ZR
6: ADD ZR ZR ZR
8: JAL 0 ZR G2
このプログラムではアドレス2の相対ジャンプでアドレス8の命令にジャンプし、アドレス8の絶対ジャンプでアドレス0の命令にジャンプします。つまりPCの値が0 -> 2 -> 8 -> 0とループすれば理想の動作ということです。 このプログラムをアセンブルし、実際に動かしてみましょう。
まずは命令メモリにアセンブルしたバイナリを格納します。
module Z16InstrMemory(
input wire i_clk,
input wire [15:0] i_addr,
output wire [15:0] o_instr
);
wire [15:0] mem[10:0];
assign o_instr = mem[i_addr[15:1]];
assign mem[0] = 16'h0040; // ADD ZR ZR G0
assign mem[1] = 16'h605D; // JRL 6 ZR G1
assign mem[2] = 16'h0000; // ADD ZR ZR ZR
assign mem[3] = 16'h0000; // ADD ZR ZR ZR
assign mem[4] = 16'h006C; // JAL 0 ZR G2
endmodule
そして以下のコマンドでシミュレーションを走らせます。
iverilog Z16CPU_tb.v Z16ALU.v Z16CPU.v Z16DataMemory.v Z16Decoder.v Z16InstrMemory.v Z16RegisterFile.v
vvp a.out
gtkwave wave.vcd
以下の波形が実際にシミュレーションを行った結果です。
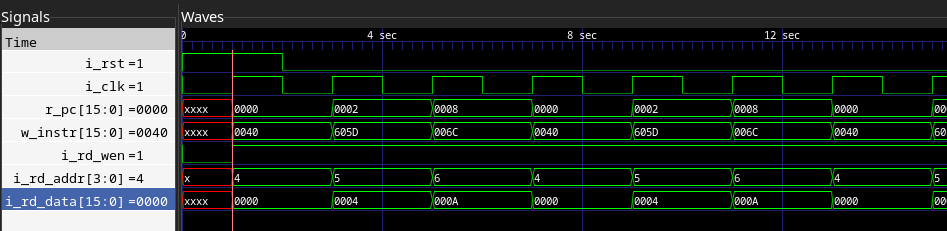
r_pcの値を見てみると0 -> 2 -> 8 -> 0とループしており、またレジスタにはジャンプ命令の次の命令のアドレスが格納されている事が確認できます。
これでジャンプ命令のデータパスが完成しました。
分岐命令
さて最後です。分岐命令のデータパスを実装しましょう。
分岐命令の動作を箇条書すると以下の通りになります。
- 命令メモリから命令をフェッチ
- デコーダが命令を解釈
- レジスタからRS1, RS2の値を読み出し
- 条件に合致する場合はPCに書き込み
意外と少ないですね。ご多分に漏れずデコーダの改造に着手しましょう。
デコーダの改造
ではデコーダの改造に着手します。
分岐命令のビットフィールドは他の命令と比べてかなり特異なものでした。
| instr | [15:8] |
[7:6] |
[5:4] |
[3:0] |
|---|---|---|---|---|
| 分岐命令 | imm[7:0] |
rs2[1:0] |
rs1[1:0] |
opcode[3:0] |
RS1とRS2のアドレスが2bitづつしか割り当てられていません。よって分岐命令のオペコードの場合はこの2bitからレジスタの抜き出す必要があります。そこで、関数get_rs1_addr()に手を加えると同時に、RS2のアドレスを抜き出す関数であるget_rs2_addr()を新たに定義します。
そしてそれぞれの関数では、分岐命令の場合は抜き出した2bitのアドレスに2'b00を結合し、4bitのアドレスを返すようにします。新たに定義したget_rs2_addr()の結果をo_rs2_addrに入力するのを忘れないようにしましょう。
assign o_opcode = i_instr[3:0];
assign o_rd_addr = i_instr[7:4];
assign o_rs1_addr = get_rs1_addr(i_instr);
assign o_rs2_addr = get_rs2_addr(i_instr);
assign o_imm = get_imm(i_instr);
assign o_rd_wen = get_rd_wen(i_instr);
assign o_mem_wen = get_mem_wen(i_instr);
assign o_alu_ctrl = get_alu_ctrl(i_instr);
function [3:0] get_rs1_addr;
input [15:0] i_instr;
begin
case(i_instr[3:0])
4'h9 : get_rs1_addr = i_instr[7:4];
4'hE : get_rs1_addr = {2'b00, i_instr[5:4]};
4'hF : get_rs1_addr = {2'b00, i_instr[5:4]};
default : get_rs1_addr = i_instr[11:8];
endcase
end
endfunction
function [3:0] get_rs2_addr;
input [15:0] i_instr;
begin
case(i_instr[3:0])
4'hE : get_rs2_addr = {2'b00, i_instr[7:6]};
4'hF : get_rs2_addr = {2'b00, i_instr[7:6]};
default : get_rs2_addr = i_instr[15:12];
endcase
end
endfunction
次にPCに加算する為の即値を命令から取り出すために、get_imm()に手を加えます。
分岐命令のビットフィールドではi_instr[15:8]の8bitが即値ですので、これを符号付き16bitに符号拡張します。
// 符号拡張
function [15:0] get_imm;
input [15:0] i_instr;
begin
case(i_instr[3:0])
4'h9 : get_imm = { {8{i_instr[15]}}, i_instr[15:8]};
4'hA : get_imm = { {12{i_instr[15]}}, i_instr[15:12]};
4'hB : get_imm = { {12{i_instr[7]}}, i_instr[7:4]};
4'hC : get_imm = { {12{i_instr[15]}}, i_instr[15:12]};
4'hD : get_imm = { {12{i_instr[15]}}, i_instr[15:12]};
4'hE : get_imm = { {8{i_instr[15]}}, i_instr[15:8]};
4'hF : get_imm = { {8{i_instr[15]}}, i_instr[15:8]};
default : get_imm = 16'h0000;
endcase
end
endfunction
分岐命令ではレジスタにもメモリにも値を書き込みませんし、ALUも利用しませんので他の関数に手を加える必要はありません。これでデコーダの改造は完了です、
デコーダの全体を以下に載せておきます。
module Z16Decoder(
input wire [15:0] i_instr,
output wire [3:0] o_opcode,
output wire [3:0] o_rd_addr,
output wire [3:0] o_rs1_addr,
output wire [3:0] o_rs2_addr,
output wire [15:0] o_imm,
output wire o_rd_wen,
output wire o_mem_wen,
output wire [3:0] o_alu_ctrl
);
assign o_opcode = i_instr[3:0];
assign o_rd_addr = i_instr[7:4];
assign o_rs1_addr = get_rs1_addr(i_instr);
assign o_rs2_addr = get_rs2_addr(i_instr);
assign o_imm = get_imm(i_instr);
assign o_rd_wen = get_rd_wen(i_instr);
assign o_mem_wen = get_mem_wen(i_instr);
assign o_alu_ctrl = get_alu_ctrl(i_instr);
function [3:0] get_rs1_addr;
input [15:0] i_instr;
begin
case(i_instr[3:0])
4'h9 : get_rs1_addr = i_instr[7:4];
4'hE : get_rs1_addr = {2'b00, i_instr[5:4]};
4'hF : get_rs1_addr = {2'b00, i_instr[5:4]};
default : get_rs1_addr = i_instr[11:8];
endcase
end
endfunction
function [3:0] get_rs2_addr;
input [15:0] i_instr;
begin
case(i_instr[3:0])
4'hE : get_rs2_addr = {2'b00, i_instr[7:6]};
4'hF : get_rs2_addr = {2'b00, i_instr[7:6]};
default : get_rs2_addr = i_instr[15:12];
endcase
end
endfunction
// 符号拡張
function [15:0] get_imm;
input [15:0] i_instr;
begin
case(i_instr[3:0])
4'h9 : get_imm = { {8{i_instr[15]}}, i_instr[15:8]};
4'hA : get_imm = { {12{i_instr[15]}}, i_instr[15:12]};
4'hB : get_imm = { {12{i_instr[7]}}, i_instr[7:4]};
4'hC : get_imm = { {12{i_instr[15]}}, i_instr[15:12]};
4'hD : get_imm = { {12{i_instr[15]}}, i_instr[15:12]};
4'hE : get_imm = { {8{i_instr[15]}}, i_instr[15:8]};
4'hF : get_imm = { {8{i_instr[15]}}, i_instr[15:8]};
default : get_imm = 16'h0000;
endcase
end
endfunction
function get_rd_wen;
input [15:0] i_instr;
begin
if(i_instr[3:0] <= 4'hA) begin
get_rd_wen = 1'b1;
end else if((i_instr[3:0] == 4'hC) || (i_instr[3:0] == 4'hD)) begin
get_rd_wen = 1'b1;
end else begin
get_rd_wen = 1'b0;
end
end
endfunction
function get_mem_wen;
input [15:0] i_instr;
begin
// STORE命令の場合にのみ1
if(4'hB == i_instr[3:0]) begin
get_mem_wen = 1'b1;
end else begin
get_mem_wen = 1'b0;
end
end
endfunction
function [3:0] get_alu_ctrl;
input [15:0] i_instr;
begin
if(i_instr[3:0] <= 4'h8) begin
get_alu_ctrl = i_instr[3:0];
end else begin
get_alu_ctrl = 4'h0;
end
end
endfunction
endmodule
条件に合致する場合はPCに書き込み
デコーダが完成しましたら、次はPCの機構に手を加えていきます。
以下のように分岐命令のオペコードの場合はRS1とRS2の値を比較し、条件に合致する場合はプログラムカウンタに即値の値を加算します。
always @(posedge i_clk) begin
if(i_rst) begin
r_pc <= 16'h0000;
end else if(w_opcode == 4'hC) begin // JAL
r_pc <= w_alu_data;
end else if(w_opcode == 4'hD) begin // JRL
r_pc <= r_pc + w_alu_data;
end else if((w_opcode == 4'hE) && (w_rs2_data == w_rs1_data)) begin // BEQ
r_pc <= r_pc + w_imm;
end else if((w_opcode == 4'hF) && (w_rs2_data > w_rs1_data)) begin // BLT
r_pc <= r_pc + w_imm;
end else begin
r_pc <= r_pc + 16'h0002;
end
end
やることは以上です。完成したCPUのコードを以下に載せておきます。
module Z16CPU(
input wire i_clk,
input wire i_rst
);
// Program Counter
reg [15:0] r_pc;
wire [15:0] w_instr;
wire [3:0] w_rd_addr;
wire [3:0] w_rs1_addr;
wire [3:0] w_rs2_addr;
wire [15:0] w_imm;
wire w_rd_wen;
wire w_mem_wen;
wire [3:0] w_alu_ctrl;
wire [3:0] w_opcode;
wire [15:0] w_rs1_data;
wire [15:0] w_rs2_data;
wire [15:0] w_rd_data;
wire [15:0] w_data_b;
wire [15:0] w_alu_data;
wire [15:0] w_mem_rdata;
always @(posedge i_clk) begin
if(i_rst) begin
r_pc <= 16'h0000;
end else if(w_opcode == 4'hC) begin // JAL
r_pc <= w_alu_data;
end else if(w_opcode == 4'hD) begin // JRL
r_pc <= r_pc + w_alu_data;
end else if((w_opcode == 4'hE) && (w_rs2_data == w_rs1_data)) begin // BEQ
r_pc <= r_pc + w_imm;
end else if((w_opcode == 4'hF) && (w_rs2_data > w_rs1_data)) begin // BLT
r_pc <= r_pc + w_imm;
end else begin
r_pc <= r_pc + 16'h0002;
end
end
Z16InstrMemory InstrMem(
.i_addr (r_pc ),
.o_instr (w_instr)
);
Z16Decoder Decoder(
.i_instr (w_instr ),
.o_opcode (w_opcode ),
.o_rd_addr (w_rd_addr ),
.o_rs1_addr (w_rs1_addr ),
.o_rs2_addr (w_rs2_addr ),
.o_imm (w_imm ),
.o_rd_wen (w_rd_wen ),
.o_mem_wen (w_mem_wen ),
.o_alu_ctrl (w_alu_ctrl )
);
assign w_rd_data = select_rd_data(w_opcode, w_mem_rdata, r_pc, w_alu_data);
function [15:0] select_rd_data;
input [3:0] i_opcode;
input [15:0] i_mem_rdata;
input [15:0] i_pc;
input [15:0] i_alu_data;
begin
case(i_opcode)
4'hA : select_rd_data = i_mem_rdata;
4'hC : select_rd_data = r_pc + 16'h0002;
4'hD : select_rd_data = r_pc + 16'h0002;
default : select_rd_data = i_alu_data;
endcase
end
endfunction
Z16RegisterFile RegFile(
.i_clk (i_clk ),
.i_rs1_addr (w_rs1_addr ),
.o_rs1_data (w_rs1_data ),
.i_rs2_addr (w_rs2_addr ),
.o_rs2_data (w_rs2_data ),
.i_rd_data (w_rd_data ),
.i_rd_addr (w_rd_addr ),
.i_rd_wen (w_rd_wen )
);
assign w_data_b = (w_opcode <= 8'h8) ? w_rs2_data : w_imm;
Z16ALU ALU(
.i_data_a (w_rs1_data ),
.i_data_b (w_data_b ),
.i_ctrl (w_alu_ctrl ),
.o_data (w_alu_data )
);
Z16DataMemory DataMem(
.i_clk (i_clk ),
.i_addr (w_alu_data ),
.i_wen (w_mem_wen ),
.i_data (w_rs2_data ),
.o_data (w_mem_rdata)
);
endmodule
これでZ16のCPUは完成しました。しかしながら安心してはいけません。動作の確認が完了して初めて完成と言えます。検証してきましょう。
動作の確認
分岐命令の動作の確認の為に、以下の1~10の総和を求めるプログラムを用いましょう。
以下のプログラムでは、最初にB1とB2を0で初期化し、総和を求めた後アドレスCでジャンプ命令を用いて停止します。
0: ADD ZR ZR B1
2: ADD ZR ZR B2
4: ADDI 10 B1
6: ADD B1 B2 B2
8: ADDI -1 B1
A: BLT B1 ZR -4
C: JRL 0 ZR G11
アセンブルしてバイナリを命令メモリに書き込みます。
module Z16InstrMemory(
input wire i_clk,
input wire [15:0] i_addr,
output wire [15:0] o_instr
);
wire [15:0] mem[10:0];
assign o_instr = mem[i_addr[15:1]];
assign mem[0] = 16'h0010; // ADD ZR ZR B1
assign mem[1] = 16'h0020; // ADD ZR ZR B2
assign mem[2] = 16'h0A19; // ADDI 10 B1
assign mem[3] = 16'h1220; // ADD B1 B2 B2
assign mem[4] = 16'hFF19; // ADDI -1 B1
assign mem[5] = 16'hFC4F; // BLT B1 ZR -4
assign mem[6] = 16'h00FD; // JRL 0 ZR G11
endmodule
そして以下のコマンドでシミュレーションを実行します。
iverilog Z16CPU_tb.v Z16ALU.v Z16CPU.v Z16DataMemory.v Z16Decoder.v Z16InstrMemory.v Z16RegisterFile.v
vvp a.out
gtkwave wave.vcd
以下の波形が実際にシミュレーションを行った結果です。

波形を見てみると、最後の方でレジスタB2に16進数で16'h0037が格納されています。これは10進数で55であり、1~10の総和です。そして最終的にr_pcの値が更新されなくなっています。これはJRLによってCPUを停止出来たという事です。理想通りの動作をしていますね。
おめでとうございます! 分岐命令の実装が完了しました!これにてZ16のCPUは完成です。お疲れ様でした。これにてあなたは友達に「俺はCPU自作したけど、お前は?」と言えるようになりました。言いましょう。
CPUを実用的にしよう
我々は動作するCPUを自作できたわけですが、現状ではお世辞にも「使える」CPUとは言い難いです。そこでこの自作CPUを実用的にするための努力をしてみましょう。
MMIO
先程1~10の総和を求めた際のように、現状では計算結果を確認するにはGTKWaveでレジスタファイルの内部信号を覗いてやる必要があります。これはあまりスマートとは言えません。そこでCPUの信号を外の世界に出力する仕組みを作りましょう。
このような場合に使える仕組みがMMIO、メモリマップドIOです。MMIOとはデータメモリのアドレスの一部に外部入出力用のレジスタを割り当てる手法の事を指します。メモリアドレスに割り当てる事により、外部にデータを出力したい場合はSTORE命令を用い、外部からのデータを得たい場合はLOAD命令を用いる事が可能となります。下図の例ではメモリの0x007AにLEDの出力が割り当てられており、ここに0x0013をストアすると1番目と2番目と5番目のLEDが点灯します。また0x007Cがボタンの入力に割り当てられており、ここから値をロードした際に1が得られた場合はボタンが押されており、0の場合はボタンが押されていない事を情報として得られます。
では実際にMMIOを実装してみましょう。今回はLEDとButtonをMMIOに割り当ててみます。
LED
まず仕様を決めます。LEDをメモリアドレスの0x007Aに割り当て、書き込む16bitのデータの内訳を下位6bitをLEDのオンオフ、上位10bitを未使用とします。
0x007A |
[15:6] |
[5:0] |
|---|---|---|
| LED | 未使用[9:0] |
LED[5:0] |
実装に移りましょう。まずはZ16CPU.vのインターフェイスに新たにo_ledを追加します。
module Z16CPU(
input wire i_clk,
input wire i_rst,
output reg [5:0] o_led
);
そしてo_ledの値を制御する新たな機構を追加します。これはメモリの書き込み制御信号w_mem_wenが1になっており、また書き込み先のアドレスが16'h007Aの場合に、o_ledの値を更新する機構になっています。
Z16DataMemory DataMem(
.i_clk (i_clk ),
.i_addr (w_alu_data ),
.i_wen (w_mem_wen ),
.i_data (w_rs2_data ),
.o_data (w_mem_rdata)
);
// MMIO
always @(posedge i_clk) begin
// LED
if(i_rst) begin
o_led <= 6'b000000;
end else if(w_mem_wen && (w_alu_data == 16'h007A)) begin
o_led <= w_rs2_data[5:0];
end else begin
o_led <= o_led;
end
end
これでLEDのMMIOの実装が完了しました。Buttonの実装に移りましょう。
Button
まず仕様を決定します。ボタンのMMIOをメモリアドレスの0x007Cに割り当て、読み出す16bitのデータの内訳を下位1bitをボタンの状態、上位15bitを未使用とします。
0x007C |
[15:1] |
[0] |
|---|---|---|
| Button | 未使用[14:0] |
Button[0] |
実装に移りましょう。まずはZ16CPU.vのインターフェイスに新たにi_buttonを追加します。
module Z16CPU(
input wire i_clk,
input wire i_rst,
input wire i_button,
output reg [5:0] o_led
);
MMIOで値を読み込む場合はLOAD命令を用いますので、読み込んだデータの書き込み先はレジスタファイルになります。そこでレジスタファイルに書き込むデータを選択する関数であるselect_rd_data()を改造します。
ここではオペコードがLOAD命令の場合であり、また計算されたアドレスw_alu_dataの値が16'h007Cの場合にi_buttonの値をw_rd_dataに接続して、レジスタファイルにボタンの状態が入力されるようにします。またi_buttonのビット幅は1bitですので、15bitの0を結合して16bitにしています。
assign w_rd_data = select_rd_data(w_opcode, i_button, w_mem_rdata, r_pc, w_alu_data);
function [15:0] select_rd_data;
input [3:0] i_opcode;
input i_button;
input [15:0] i_mem_rdata;
input [15:0] i_pc;
input [15:0] i_alu_data;
begin
case(i_opcode)
4'hA : begin
if(w_alu_data == 16'h007C) begin // MMIO Button
select_rd_data = {15'b000_0000_0000_0000, i_button};
end else begin
select_rd_data = i_mem_rdata;
end
end
4'hC : select_rd_data = r_pc + 16'h0002;
4'hD : select_rd_data = r_pc + 16'h0002;
default : select_rd_data = i_alu_data;
endcase
end
endfunction
Z16RegisterFile RegFile(
.i_clk (i_clk ),
.i_rs1_addr (w_rs1_addr ),
.o_rs1_data (w_rs1_data ),
.i_rs2_addr (w_rs2_addr ),
.o_rs2_data (w_rs2_data ),
.i_rd_data (w_rd_data ),
.i_rd_addr (w_rd_addr ),
.i_rd_wen (w_rd_wen )
);
以上でMMIOの実装が完了しました。全体のコードを以下に載せておきます。
module Z16CPU(
input wire i_clk,
input wire i_rst,
input wire i_button,
output reg [5:0] o_led
);
// Program Counter
reg [15:0] r_pc;
wire [15:0] w_instr;
wire [3:0] w_rd_addr;
wire [3:0] w_rs1_addr;
wire [3:0] w_rs2_addr;
wire [15:0] w_imm;
wire w_rd_wen;
wire w_mem_wen;
wire [3:0] w_alu_ctrl;
wire [3:0] w_opcode;
wire [15:0] w_rs1_data;
wire [15:0] w_rs2_data;
wire [15:0] w_rd_data;
wire [15:0] w_data_b;
wire [15:0] w_alu_data;
wire [15:0] w_mem_rdata;
always @(posedge i_clk) begin
if(i_rst) begin
r_pc <= 16'h0000;
end else if(w_opcode == 4'hC) begin // JAL
r_pc <= w_alu_data;
end else if(w_opcode == 4'hD) begin // JRL
r_pc <= r_pc + w_alu_data;
end else if((w_opcode == 4'hE) && (w_rs2_data == w_rs1_data)) begin // BEQ
r_pc <= r_pc + w_imm;
end else if((w_opcode == 4'hF) && (w_rs2_data > w_rs1_data)) begin // BLT
r_pc <= r_pc + w_imm;
end else begin
r_pc <= r_pc + 16'h0002;
end
end
Z16InstrMemory InstrMem(
.i_addr (r_pc ),
.o_instr (w_instr)
);
Z16Decoder Decoder(
.i_instr (w_instr ),
.o_opcode (w_opcode ),
.o_rd_addr (w_rd_addr ),
.o_rs1_addr (w_rs1_addr ),
.o_rs2_addr (w_rs2_addr ),
.o_imm (w_imm ),
.o_rd_wen (w_rd_wen ),
.o_mem_wen (w_mem_wen ),
.o_alu_ctrl (w_alu_ctrl )
);
assign w_rd_data = select_rd_data(w_opcode, i_button, w_mem_rdata, r_pc, w_alu_data);
function [15:0] select_rd_data;
input [3:0] i_opcode;
input i_button;
input [15:0] i_mem_rdata;
input [15:0] i_pc;
input [15:0] i_alu_data;
begin
case(i_opcode)
4'hA : begin
if(w_alu_data == 16'h007C) begin // MMIO Button
select_rd_data = {15'b000_0000_0000_0000, i_button};
end else begin
select_rd_data = i_mem_rdata;
end
end
4'hC : select_rd_data = r_pc + 16'h0002;
4'hD : select_rd_data = r_pc + 16'h0002;
default : select_rd_data = i_alu_data;
endcase
end
endfunction
Z16RegisterFile RegFile(
.i_clk (i_clk ),
.i_rs1_addr (w_rs1_addr ),
.o_rs1_data (w_rs1_data ),
.i_rs2_addr (w_rs2_addr ),
.o_rs2_data (w_rs2_data ),
.i_rd_data (w_rd_data ),
.i_rd_addr (w_rd_addr ),
.i_rd_wen (w_rd_wen )
);
assign w_data_b = (w_opcode <= 8'h8) ? w_rs2_data : w_imm;
Z16ALU ALU(
.i_data_a (w_rs1_data ),
.i_data_b (w_data_b ),
.i_ctrl (w_alu_ctrl ),
.o_data (w_alu_data )
);
Z16DataMemory DataMem(
.i_clk (i_clk ),
.i_addr (w_alu_data ),
.i_wen (w_mem_wen ),
.i_data (w_rs2_data ),
.o_data (w_mem_rdata)
);
// MMIO
always @(posedge i_clk) begin
// LED
if(i_rst) begin
o_led <= 6'b000000;
end else if(w_mem_wen && (w_alu_data == 16'h007A)) begin
o_led <= w_rs2_data[5:0];
end else begin
o_led <= o_led;
end
end
endmodule
動作の確認
動作の確認に移りましょう。まずはLEDの動作を確認します。以下のテスト用のプログラムでは1~5の総和を求めた後、LEDのMMIOのアドレスである122(0x007A)に計算結果をストアし、停止しています。
00: ADD ZR ZR B1
02: ADD ZR ZR B2
04: ADDI 5 B1
06: ADD B1 B2 B2
08: ADDI -1 B1
0A: BLT B1 ZR -4
0C: ADD ZR ZR G0
0E: ADDI 122 G0
10: STORE B2 G0 0
12: JRL 0 ZR G11
上記のプログラムをアセンブルし、バイナリを命令メモリに書き込みます。
module Z16InstrMemory(
input wire i_clk,
input wire [15:0] i_addr,
output wire [15:0] o_instr
);
wire [15:0] mem[10:0];
assign o_instr = mem[i_addr[15:1]];
assign mem[0] = 16'h0010; // ADD ZR ZR B1
assign mem[1] = 16'h0020; // ADD ZR ZR B2
assign mem[2] = 16'h0519; // ADDI 5 B1
assign mem[3] = 16'h1220; // ADD B1 B2 B2
assign mem[4] = 16'hFF19; // ADDI -1 B1
assign mem[5] = 16'hFC4F; // BLT B1 ZR -4
assign mem[6] = 16'h0040; // ADD ZR ZR G0
assign mem[7] = 16'h7A49; // ADDI 122 G0
assign mem[8] = 16'h240B; // STORE B2 G0 0
assign mem[9] = 16'h00FD; // JRL 0 ZR G11
endmodule
そしてテストベンチZ16CPU_tb.vを改造してo_ledを接続します。
module Z16CPU_tb;
reg i_clk = 1'b0;
reg i_rst = 1'b0;
wire [5:0] o_led;
always #1 begin
i_clk <= ~i_clk;
end
initial begin
$dumpfile("wave.vcd");
$dumpvars(0, Z16CPU_tb);
end
Z16CPU CPU(
.i_clk (i_clk ),
.i_rst (i_rst ),
.o_led (o_led )
);
initial begin
// リセット
i_rst = 1'b1;
#2
// リセットを落とし、実行開始
i_rst = 1'b0;
#100
$finish;
end
endmodule
そして以下のコマンドでシミュレーションを実行します。
iverilog Z16CPU_tb.v Z16ALU.v Z16CPU.v Z16DataMemory.v Z16Decoder.v Z16InstrMemory.v Z16RegisterFile.v
vvp a.out
gtkwave wave.vcd
実際にシミュレーションを走らせた結果が以下の波形です。数クロックの後、o_ledに16進数で0xFが出力されています。これは10進数で15であり、1~5の総和に一致しています。これで計算結果を外部に出力出来るようになりました。
続いてボタンのMMIOの動作確認を行いましょう。今回はテスト用プログラムとして、ボタンが押されるまではLEDに出力される値をひたすらカウントアップしていくプログラムを使いましょう。
動作を理解しやすくするために疑似コードを書きます。
x = 0;
led = 122;
button = 124;
while(1){
x = x + 1;
Mem[led] = x;
if(Mem[button] == 1) {
stop();
}
}
そのあとこの疑似コードをZ16のアセンブリに人力コンパイルします。解読しなくて結構です、適当に斜め読みしてコピペしてください。コンパイラ欲しいですね。
00: ADD ZR ZR B1 // B1 <- 0
02: ADDI 1 B1 // B1 <- B1 + 1
04: ADD ZR ZR G0 // G0 <- 0
06: ADDI 122 G0 // G0 <- G0 + 122
08: ADD ZR ZR G1 // G1 <- 0
0A: ADDI 124 G1 // G1 <- G1 + 124
0C: ADD ZR ZR G3 // G3 <- 0
0E: ADDI -8 G3 // G3 <- -8
10: ADD ZR ZR G2 // G2 <- 0
12: ADDI 1 G2 // G2 <- G2 + 1
14: STORE G2 G0 0 // [LED] <- G2
16: LOAD 0 G1 B2 // B2 <- [Button]
18: BEQ B1 B2 4 // if B1 == B2, then PC <- PC + 4
1A: JRL 0 G3 ZR // PC <- PC + G3
1C: JRL 0 ZR G11 // STOP
そしてこれをアセンブルし、バイナリを命令メモリに書き込みます。
module Z16InstrMemory(
input wire i_clk,
input wire [15:0] i_addr,
output wire [15:0] o_instr
);
wire [15:0] mem[14:0];
assign o_instr = mem[i_addr[15:1]];
assign mem[0] = 16'h0010; // ADD ZR ZR B1 // B1 <- 0
assign mem[1] = 16'h0119; // ADDI 1 B1 // B1 <- B1 + 1
assign mem[2] = 16'h0040; // ADD ZR ZR G0 // G0 <- 0
assign mem[3] = 16'h7A49; // ADDI 122 G0 // G0 <- G0 + 122
assign mem[4] = 16'h0050; // ADD ZR ZR G1 // G1 <- 0
assign mem[5] = 16'h7C59; // ADDI 124 G1 // G1 <- G1 + 124
assign mem[6] = 16'h0070; // ADD ZR ZR G3 // G3 <- 0
assign mem[7] = 16'hF879; // ADDI -8 G3 // G3 <- -8
assign mem[8] = 16'h0060; // ADD ZR ZR G2 // G2 <- 0
assign mem[9] = 16'h0169; // ADDI 1 G2 // G2 <- G2 + 1
assign mem[10] = 16'h640B; // STORE G2 G0 0 // [LED] <- G2
assign mem[11] = 16'h052A; // LOAD 0 G1 B2 // B2 <- [Button]
assign mem[12] = 16'h046E; // BEQ B1 B2 4 // if B1 == B2, then PC <- PC + 4
assign mem[13] = 16'h070D; // JRL 0 G3 ZR // PC <- PC + G3
assign mem[14] = 16'h00FD; // JRL 0 ZR G11 // STOP
endmodule
次にテストベンチを改造し、i_buttonを定義してCPUに接続します。そしてCPUを動かし始めてから100クロック後にi_buttonに1を入力し、20クロック後に0にするように信号を制御します。
module Z16CPU_tb;
reg i_clk = 1'b0;
reg i_rst = 1'b0;
reg i_button = 1'b0;
wire [5:0] o_led;
always #1 begin
i_clk <= ~i_clk;
end
initial begin
$dumpfile("wave.vcd");
$dumpvars(0, Z16CPU_tb);
end
Z16CPU CPU(
.i_clk (i_clk ),
.i_rst (i_rst ),
.i_button (i_button ),
.o_led (o_led )
);
initial begin
// リセット
i_rst = 1'b1;
#2
// リセットを落とし、実行開始
i_rst = 1'b0;
#100
// 100クロック後にボタンを押す
i_button = 1'b1;
#20
// 20クロック後にボタンを離す
i_button = 1'b0;
#100
$finish;
end
endmodule
後はいつものコマンドでシミュレーションを実行します。
iverilog Z16CPU_tb.v Z16ALU.v Z16CPU.v Z16DataMemory.v Z16Decoder.v Z16InstrMemory.v Z16RegisterFile.v
vvp a.out
gtkwave wave.vcd
以下の波形が実際にシミュレーションを行った結果です。
プログラムの実行開始時からLED出力がカウントアップされ、ボタンが押された途端にカウントが停止しました。自作CPU上でプログラムが意図した通りに動きましたね、最高の気分です。
これで我々の自作CPUはボタン入力とLED出力を兼ね備えた物となりました。素晴らしい。
実機向け:自作CPUを実機で動かす
では我々の作り出したCPUを現実に存在させましょう。
ラッパーの作成
現在、命令メモリであるZ16InstrMemory.vの中にはLEDの値をカウントアップするプログラムが入っています。よって今までに我々が作ったCPUをFPGAに書き込むと、FPGAボードに載っているLEDが000000 -> 000001 -> 000010 -> ...と光る筈です。
ただ問題があり、それは我々が使うFPGAボードであるTang Nano 9Kは、デフォルトでは27MHzのクロックしか使えない事です。27MHzのクロックとは1秒間に27000000回振動する信号であり、これを我々のCPUのi_clkに接続すると、LEDが1秒間に2700万回変化する事になります。これでは正しく動作しているか目視で確認する事が出来ません。
CPUは27MHzの速度に耐えられますが、LEDの変化速度に人間の動体視力が耐えられないという訳ですね。
またもう一つ問題というか対処すべきTang Nano 9Kの仕様があります。Tang Nano 9KのLEDとボタンは両方とも負論理という仕様です。これにより、LEDのピンに0を出力するとLEDが光り、1を出力するとLEDの光が消えます。またボタンが押されている時はボタンのピンから0が入力され、押されていない時は1が入力されます。我々が作成したZ16CPUのi_rstとi_buttonは、それぞれTang Nano 9Kの2つあるボタンに繋げる予定ですので、これをそのまま接続するとZ16CPUのi_buttonとi_rstが、ボタンが押されていない状態では1が入力される事になってしまいます。これでは使い辛いです。
以上で挙げたように、CPUを実装するFPGAボード由来の解決すべき問題がいくつか存在します。
そこで、Z16CPUを包み込むモジュールであるZ16CPU_wrapper.vを新たに作り、そこで先で挙げた問題に対処することにしましょう。
まずはZ16CPU_wrapper.vという名前のVerilogファイルを作成してください。
そしてZ16CPU.vと同じ入出力を定義します。
module Z16CPU_wrapper(
input wire i_clk,
input wire i_rst,
input wire i_button,
output wire [5:0] o_led
);
// ここに回路を記述
endmodule
ではまずはクロック速度に対処します。今回は27MHzのクロックから10Hzのクロックを生成します。r_clkとr_counterというレジスタを新たに定義し、0で初期化します。
reg r_clk = 1'b0;
reg [31:0] r_counter = 32'h00000000;
そして、入力クロックの立ち上がりエッジの数をr_counterでカウントし、135万回になったらr_clkの値を反転する事で、r_clkの値が10MHzのクロックになります。
always @(posedge i_clk) begin
if(r_counter == 32'd1350000) begin
r_counter <= 32'h00000000;
r_clk <= ~r_clk;
end else begin
r_counter <= r_counter + 32'h00000001;
r_clk <= r_clk;
end
end
次にLEDとボタンの負論理に対処します。まずはLED x 2とボタンの信号を中継するための信号線のw_rst、w_button、w_ledを定義します。
wire w_rst;
wire w_button;
wire [5:0] w_led;
そしてLEDへの出力と、ボタンの入力を全て反転します。
assign w_rst = ~i_rst;
assign w_button = ~i_button;
assign o_led = ~w_led;
最後に作成したCPUに対して各種信号を接続します。これで全ての問題に対処できました。
Z16CPU CPU(
.i_clk (r_clk ),
.i_rst (w_rst ),
.i_button (w_button ),
.o_led (w_led )
);
Z16CPU_wrapper.vのコード全体を以下に載せておきます。
module Z16CPU_wrapper(
input wire i_clk,
input wire i_rst,
input wire i_button,
output wire [5:0] o_led
);
wire w_rst;
wire w_button;
wire [5:0] w_led;
reg [31:0] r_counter = 32'h00000000;
reg r_clk = 1'b0;
always @(posedge i_clk) begin
if(r_counter == 32'd1350000) begin
r_counter <= 32'h00000000;
r_clk <= ~r_clk;
end else begin
r_counter <= r_counter + 32'h00000001;
r_clk <= r_clk;
end
end
assign w_rst = ~i_rst;
assign w_button = ~i_button;
assign o_led = ~w_led;
Z16CPU CPU(
.i_clk (r_clk ),
.i_rst (w_rst ),
.i_button (w_button ),
.o_led (w_led )
);
endmodule
次はEDAでFPGAに書き込んでいきます。
EDAを使う
Gowin EDAを起動しZ16CPUという名前でプロジェクトを作成します。Gowin EDAの使い方はディジタル回路とVerilog入門#プロジェクト作成を参照してください。
プロジェクトを作成しましたら、Designのプロジェクトを右クリックし、Add Files...から以下の今まで作成したVerilogファイルをプロジェクトに追加します。
- Z16CPU_wrapper.v
- Z16CPU.v
- Z16RegisterFile.v
- Z16DataMemory.v
- Z16InstrMemory.v
- Z16ALU.v
- Z16Decoder.v
そして論理合成を実行しましょう。10秒程で終わるはずです。
Tools > Schematic Viewer > RTL Design Viewerから回路図を開き、黄色で示されているCPUをダブルクリックしてCPUの回路図を覗くとCPUっぽい何かが見られて嬉しいです。
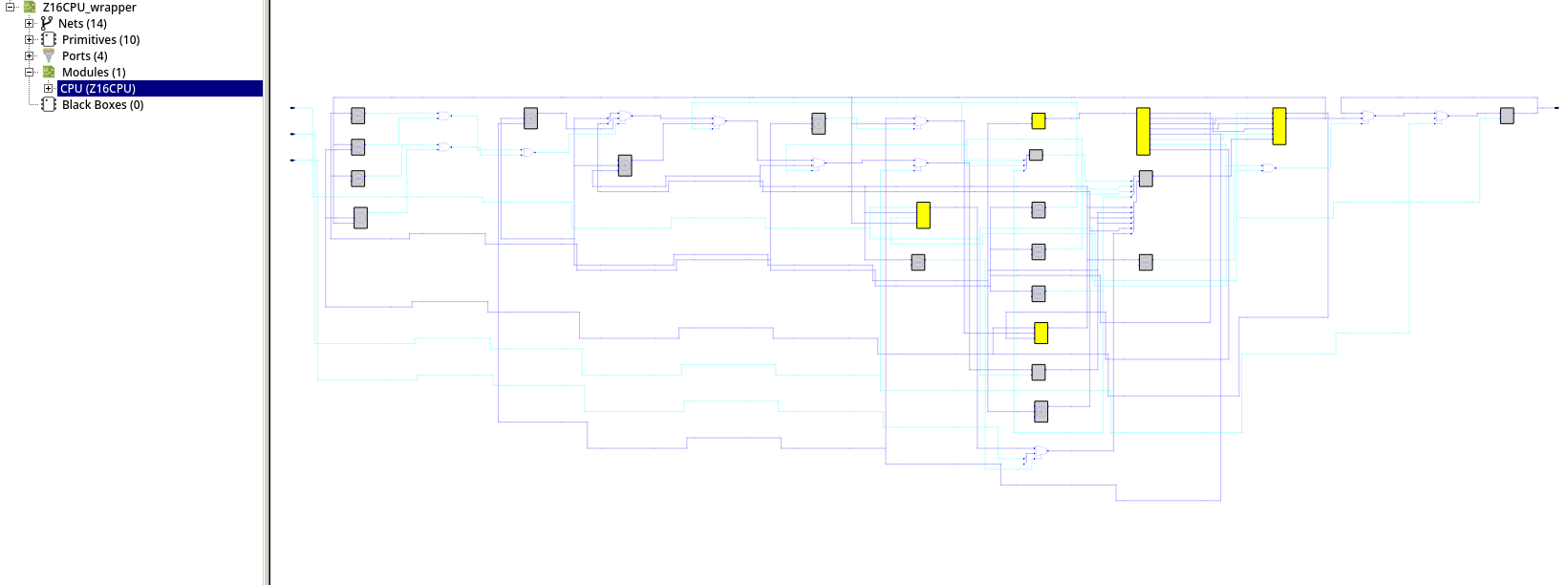
次にピンアサインを行います。FloorPlannerを起動し、I/O Constraintsから以下の表に従ってピンアサインを行ってください。
| ピン | インターフェイス | ピン番号 |
|---|---|---|
| クロック(27MHz) | i_clk |
52 |
| ボタン(S1) | i_rst |
4 |
| ボタン(S2) | i_button |
3 |
| LED0 | o_led[0] |
10 |
| LED1 | o_led[1] |
11 |
| LED2 | o_led[2] |
13 |
| LED3 | o_led[3] |
14 |
| LED4 | o_led[4] |
15 |
| LED5 | o_led[5] |
16 |
完了したら、Ctrl + Sで上書き保存を忘れないでください。
次に配置配線を実行しましょう。これはかなり時間が掛かります。筆者の環境では3分掛かりました。
たかが3分と言っても書いたVerilogにバグがあり、実機でのデバッグを行わなければならない時にこの3分は非常にストレスになります。修正をしてから結果が出るまでにカップラーメンを作れる時間が掛かると一日なんて平気で溶けますので、今までのようにシミュレータで消せるバグは先に消しておくのが賢い選択です。
配置配線が終わりましたら、Programmerを起動してFPGAに書き込みましょう。書き込みが完了するとTang Nano 9K上で我々が作成したCPUが生成されます。
ボタン(S1)を押してリセットをしてみたり、ボタン(S2)を押してカウントを停止させてみたりしてください。

お疲れ様でした。これで自作CPUを現実世界に顕現させる事が出来ました。おめでとうございます。
CPUを高速にしよう
実用的でないCPUはカスですが、遅いCPUもカスです。ここでは偉大な先人たちが作り出した高速なCPUを作るための技術を紹介いたします。実装はしません。
パイプライン化
演算命令において、我々の作ったCPUは主に4つのステージに分けることが出来ます。まずは命令をフェッチするIF(Instruction Fetch)ステージ、そして命令をデコードするID(Instruction Decode)ステージ、次に命令を実行するEX(Execute)ステージ、最後に計算結果をレジスタに書き戻すWB(Write Back)ステージです。
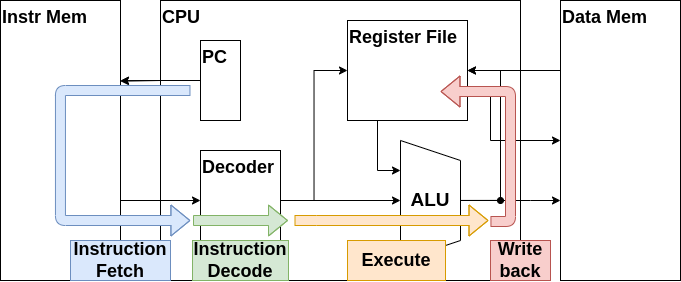
我々が作成したZ16 CPUは、この4つのステージの処理を1クロックで行うシングルサイクルプロセッサでした。しかしながら1クロックで全てのステージの処理を行うため、1クロックの間にデータが通るべきデータパスが長くなり、クロックの周波数を上げて高速に動作させるのが非常に難しいという欠点があります。
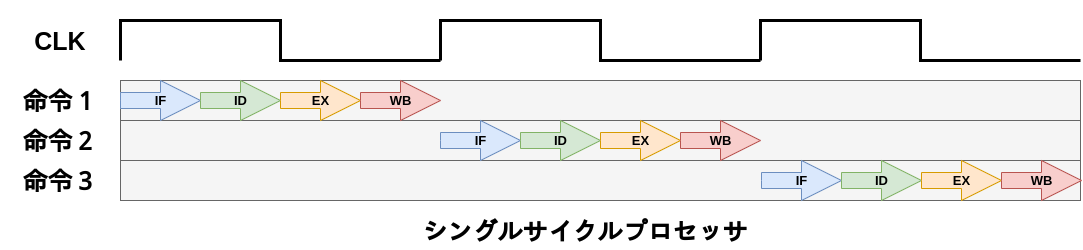
そこで、各ステージの境目にレジスタを追加し、1クロックで1ステージだけ処理を行うようにします。
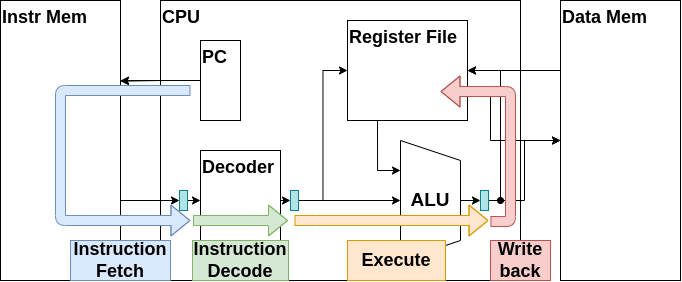
そうすると、1クロックの間にデータが通るべきデータパスが短くなり、容易に動作周波数を上げる事が出来ます。
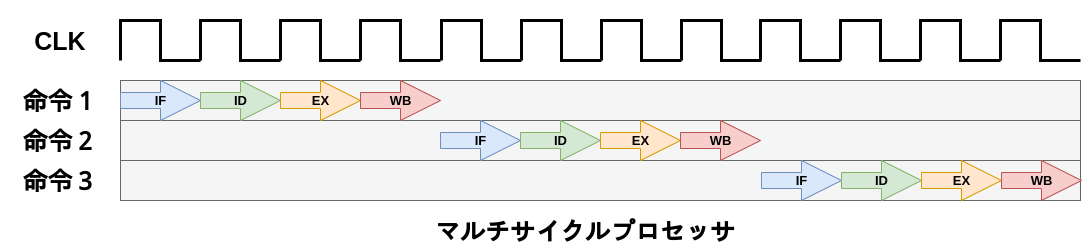
ただこの場合、動作周波数を4倍に出来ても1つの命令を実行するのに4クロック必要になり、結果的に処理速度は変わりません。これでは意味がありません。
そこで更に改造を加え、各ステージで並列に処理を行うようにします。つまり命令1をデコードしている間に命令2をフェッチし、次のクロックでは命令1が実行されている間に命令2がデコードされ、それと同時に命令3がフェッチされます。
このようにCPUのデータパスを各ステージに分割し、それぞれのステージを並列に動作させる技法をパイプライン化と呼びます。
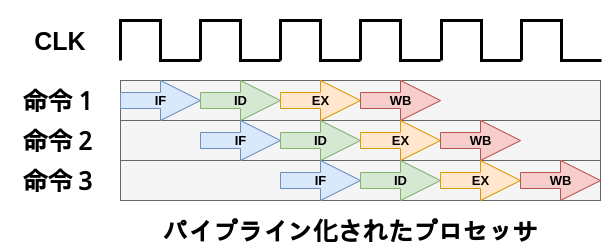
マルチサイクルの例では、命令1から命令3が完了するまでに12クロック掛かっていました。これをパイプライン化した結果、6クロックで処理が完了しています。なんと2倍の性能向上です。ヤバいですね。
残念ながらこれは理想的な場合です。実際に素朴なパイプライン化を行うと、データハザードや構造ハザード、制御ハザードといった様々な問題が発生します。ただこれらの問題もフォワーディングなどの技法を通して解決が可能です。最高ですね。
OoO実行
OoO実行という高速化技法を説明します。これはOut-of-Order実行の略で、簡単に言うと命令の順序を変えて高速に実行できるようにする高速化技法です。例として以下の命令列を考えます。1つの命令の実行に1サイクル掛かると仮定して、この命令列は実行するのに計6サイクル掛かります。
サイクル0とサイクル1の命令を見ると、この2つの命令の間にはG2についてデータ依存が存在しています。つまりSUB命令はADD命令が計算するG2の値が必要であるため、当然SUB命令はADD命令より先に実行することは不可能です。
しかし、その下のサイクル2とサイクル3の命令を見てみると、この2つの命令の間にはデータ依存は存在してません。
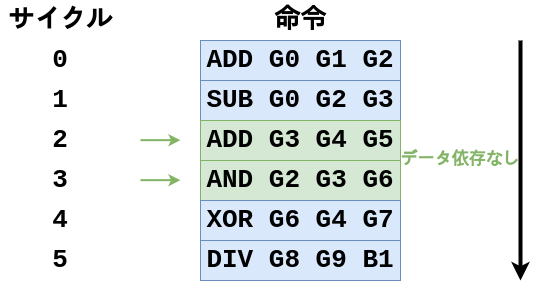
つまりこの2つの命令は同時に実行することが可能です。してしまいましょう。この操作によって1サイクルだけ高速に実行できるようになりました。
ただ更によく見てみると、一番下のDIV命令は命令列のどの命令に対してもデータ依存を持っていません。
よって一番最初に実行しても何も問題ありません。してしまいましょう。
命令の実行順序を変えることで、結果的に2サイクル分も高速化することが出来ました。嬉しいですね。これをOut-of-Order実行と呼びます。
そもそもどうやって2つの命令を同時に実行するのか、レジスタファイルは2読み出し1書き込みの構造ではないのか、など様々な疑問が浮かんでいると思います。答えは簡単で、ALUの数を増やしたりVerilogを書き換えてレジスタファイルの構造を変えてやれば良いです。更に具体的な知識が欲しければTomasuloのアルゴリズムやScoreboardingで調べれば出てきます。出てこない気がしてきた。頑張ってください。
更なる速さを求める
コンピュータアーキテクチャの世界においてパイプライン化やOut-of-Order実行は氷山の一角に過ぎず、計算機の高速化を求めた先人たちの様々な高速化技法が存在しています。シングルサイクルの16bitのCPUを作って満足ですか?更なる速さを求めたくはありませんか?加速しましょう。
Hisa Ando大先生の最強の本がオススメです。重版してくれんかな。
この次へ
無から始める自作CPUの最後では、自作CPUのその後にどんな事がやれるのか少しだけ紹介します。
Copyright (C) Cra2yPierr0t, ALL RIGHTS RESERVED